
Breaking: Claude Sonnet 3.7 is available in SmythOS AI agent building platform as of 2-25-2027. Build Claude 3.7 Sonnet AI Agents with SmythOS.
Claude 3.7 Sonnet is the latest large language model (LLM) from Anthropic, unveiled in late February 2025. Anthropic describes it as their “most intelligent” AI model yet. It introduces a unique hybrid reasoning approach, combining rapid responses with deeper, step-by-step “thinking” in a single system. In this report, we provide an in-depth analysis of Claude 3.7 Sonnet, covering its technical specs, performance benchmarks, use cases, user feedback, pricing and adoption, recent developments, and a balanced look at strengths and limitations. All information is current as of this writing.
| Feature | Details |
|---|---|
| Release Date | February 2025 |
| Context Window | 200,000 tokens |
| Subscription Cost | $20/month for Claude Pro subscription |
| API Pricing | $15 per million input tokens, $75 per million output tokens |
| Speed | Faster than Claude 3 Opus, slightly slower than Claude 3.5 Haiku |
| Reasoning Ability | Enhanced reasoning mode for Pro accounts |
| Token Processing | ~1,000 tokens per second |
| Multimodal Capabilities | Advanced image understanding, document analysis |
| Knowledge Cutoff | October 2024 |
| Training Focus | Real-world task reliability, error reduction |
| Strengths | Complex reasoning, coding accuracy, planning |
| Code Generation | Significant improvements in error reduction |
| API Integration | Available via REST API (claude-3-7-sonnet-20250219) |
| Key Competitors | GPT-4o, Gemini Ultra |
| Key Early Adopters | Canva, Vercel, Cognition, SmythOS |
| Benchmark Performance | Top-tier on reasoning, coding, and math evaluations |
| Documentation | docs.anthropic.com |
Technical Specifications and Key Features
Claude 3.7 Sonnet is a frontier-grade LLM built on Anthropic’s Claude 3 architecture. Key technical specs and features include:
Scale and Architecture
It is a very large transformer-based model with on the order of 100+ billion parameters (Claude 3.5 Sonnet was about 175B parameters). It supports an extremely large context window of up to 200,000 tokens, allowing it to ingest lengthy documents or transcripts far beyond what most models can handle. The model is multi-modal as well – it can parse and analyze images, charts, PDFs and other visual data in prompts, on par with other leading vision-enabled models.
Hybrid “Extended Thinking” Mode
Claude 3.7’s standout feature is its ability to operate in two modes: a standard fast mode and a new extended thinking mode. In standard mode, it responds near-instantly like a normal chatbot. In extended mode, it engages in a more detailed chain-of-thought reasoning process before finalizing its answer. This internal reasoning is even made visible to the user in the interface (so you can watch it “think” step by step). The user can toggle this mode on/off or even set a custom “thinking time” budget via the API, controlling how many tokens/time the model spends reasoning (up to 128k tokens devoted to reasoning steps). This hybrid approach is unique – Anthropic is the first to offer a single model that lets users “balance speed and quality” on the fly by choosing quick answers vs. advanced reasoning within one AI.
Reasoning and Accuracy Improvements
In extended thinking mode, Claude 3.7 will self-reflect and break down complex problems, which greatly improves performance on tasks like math, physics, and multi-step logic puzzles. Essentially, it can approach problems more like a human expert would – taking time to analyze – rather than just guessing an answer. Anthropic notes this unified approach (fast vs. reflective in one model) is inspired by how the human brain handles some questions with immediate answers and others with careful thought. They deliberately designed Claude 3.7 to integrate reasoning as an internal capability instead of offloading it to a separate slower model. The result is a more seamless user experience, since you no longer need to pick a different AI for “thinking slow” – it’s all Claude.
Coding Capabilities and Tools
Claude 3.7 Sonnet delivers significant improvements in coding and software development tasks. It was trained with a focus on real-world programming challenges, and it shows strong gains in writing and debugging code. Alongside the model, Anthropic introduced Claude Code, a command-line tool (in limited preview) that lets developers use Claude as an “agentic” coding assistant. Claude Code can browse and modify codebases, run tests, use command-line tools, and even commit changes to GitHub, all while keeping the developer in the loop at each step. Early results show it can handle tasks like test-driven development and refactoring that normally take an engineer 45+ minutes in a single automated pass. This makes Claude a powerful pair programmer and software agent. Even without Claude Code, the base model itself excels at code generation, understanding large code contexts, and using tools when appropriately prompted.
“Agentic” Actions and Integration
Beyond coding, Claude 3.7 is built to work with tools and act autonomously when needed. Anthropic describes new “agentic computer use” abilities – the model can follow instructions to perform multi-step tasks like searching documents, controlling APIs or performing workflows (with proper safeguards). This is facilitated by its extended reasoning and large memory, allowing it to plan and execute sequences of actions. In practice, this means Claude 3.7 is well-suited to power AI agents (e.g. customer service bots, research assistants, workflow automations) that need both speed and reasoning. The model’s attributes specifically list Reasoning, Text generation, Code generation, Rich text formatting, and Agentic computer use as core strengths.
Other Features
Claude 3.7 continues to provide the high-quality natural language generation Claude is known for – it produces very fluent, human-like responses. It can output well-formatted content (Markdown, lists, etc.) and handle rich text formatting which is useful for creating reports or HTML content. It supports over a dozen languages with high proficiency (English, Spanish, French, Japanese, etc., similar to Claude 3’s multilingual abilities). The model’s knowledge cutoff is updated through late 2024, so it has relatively current information in its training (though it does not yet have live internet access – see limitations). In terms of interface, Claude 3.7 is accessible via a chat web app (Claude.ai) as well as through an API and partner platforms (details in the Pricing & Availability section). Anthropic has also significantly improved Claude’s safety and reliability in this version (see below), refining how it handles harmful or sensitive prompts.
In summary, Claude 3.7 Sonnet’s technical profile is that of a state-of-the-art general-purpose AI with an innovative twist: it marries the speed of an instant-answer assistant with the depth of a reasoning engine. Its massive context window, tool-use abilities, and coding skills make it a robust AI for a wide range of tasks, from chitchat and writing to debugging code and analyzing data, all within a single model.
Performance Metrics and Comparison with Other AI Models
Claude 3.7 Sonnet delivers top-tier performance on many benchmarks and shows competitive results against other leading AI models in the field. Anthropic and independent testers report the following performance highlights:
State-of-the-Art Benchmark Results
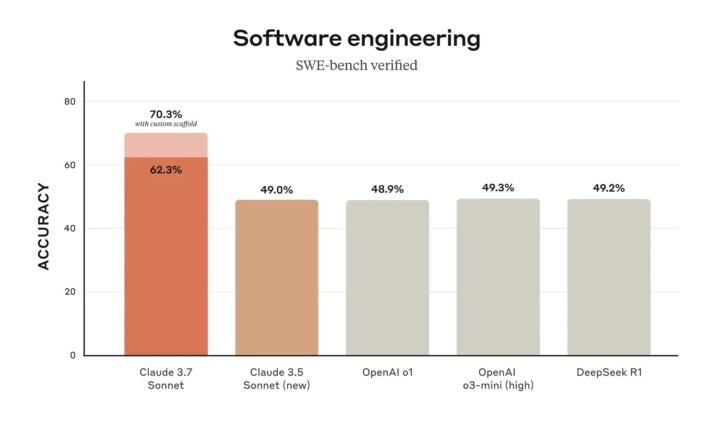
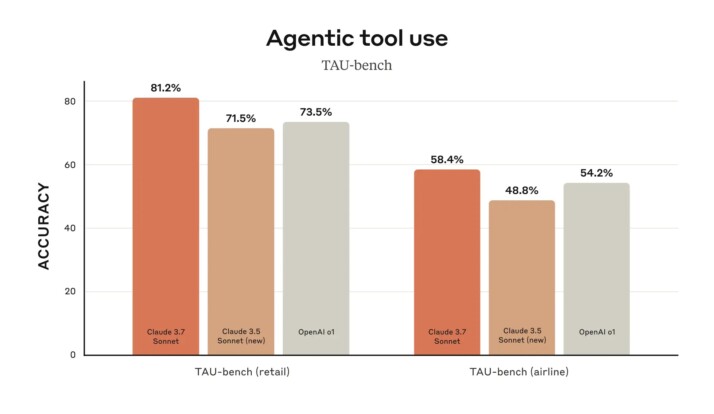
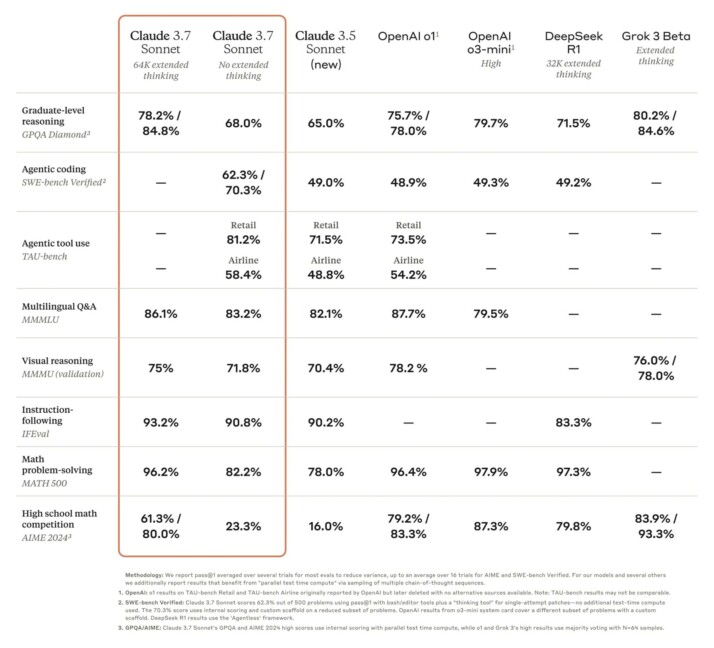
Claude 3.7 has achieved state-of-the-art scores on multiple challenging evaluations. For example, it ranked at the top on SWE-Bench (Verified), a benchmark that tests an AI’s ability to solve real-world software engineering issues. This indicates Claude’s coding and problem-solving improvements are not just theoretical – it outperforms other models in handling complex, realistic coding tasks. It also set state-of-the-art on TAU-Bench, a framework for evaluating AI agents performing complex multi-step tasks with tool use and user interaction. In Anthropic’s internal testing, Claude 3.7 excelled across dimensions like instruction-following, general reasoning, multimodal understanding, and agentic coding. Notably, the extended thinking mode gives it a significant boost on math and science problems, where it can reason through solutions more effectively. In fact, Anthropic amusingly noted that Claude 3.7 even beat all their previous models at a Pokémon game-playing challenge they use to test strategic reasoning – a fun but telling sign of more advanced planning capabilities.
Real-World Task Performance
Early access users and partner companies have praised Claude 3.7’s gains on practical tasks. The team behind Cursor (an AI code editor) found that Claude 3.7 is “once again best-in-class for real-world coding tasks,” handling complex codebases and advanced tool use better than any model they’ve tried. AI dev firm Cognition reported Claude 3.7 is “far better than any other model” at planning code changes and doing full-stack updates. Vercel highlighted Claude’s exceptional precision in orchestrating complex software agent workflows. The coding platform Replit has already deployed Claude 3.7 to build web apps and dashboards from scratch, noting that other models stall out on these tasks where Claude succeeds. Even design tool maker Canva, in their evals, found Claude’s code generation so reliable that it produced production-ready front-end code with “superior design taste and drastically reduced errors,” outperforming prior models. These testimonials reinforce that on applied benchmarks (and not just academic tests), Claude 3.7’s performance is leading.
Comparisons to OpenAI’s Models
Anthropic positions Claude as a direct competitor to OpenAI’s GPT-4/ChatGPT and Google’s Gemini models. In terms of raw capabilities, Claude 3.7 is certainly in the same league as these frontier models. It handles a wide array of tasks from creative writing to complex Q&A at high proficiency. One notable difference is Claude’s hybrid reasoning feature – OpenAI’s ChatGPT (GPT-4) does not natively offer a user-toggleable reasoning mode that shows its chain-of-thought. ChatGPT tends to keep its reasoning hidden “behind the scenes” and focus on delivering a fast final answer. By contrast, Claude (like xAI’s Grok, discussed below) is more transparent when doing deep reasoning, which can be an advantage for users who want to see the thought process or verify each step. As for benchmark comparisons, OpenAI hasn’t released a direct counterpart to Claude’s hybrid model yet. However, on many standard NLP benchmarks (like MMLU knowledge tests, GSM8K math, coding tasks, etc.), the top Claude 3 variant (Opus) and GPT-4 are often close. For example, Anthropic previously showed Claude 3 Opus slightly outscoring GPT-4 on a range of academic and coding benchmarks, while GPT-4 still led on some creative and common-sense tasks. With Claude 3.7 Sonnet being an upgrade to the mid-tier model, we can expect it now rivals or exceeds the earlier top-tier in many areas. In short, Claude 3.7 is on par with the best of GPT-4 for most tasks, and its unique features offer a differentiator.
Comparisons to xAI’s Grok 3
Elon Musk’s startup xAI released Grok-3, another advanced model, which is positioned as a reasoning specialist. Grok-3 introduced its own “Think Mode” to show step-by-step logic, similar in spirit to Claude’s extended mode. Grok has claimed impressive benchmark wins, particularly in mathematical and logical reasoning: for instance, Grok 3 scored 52 in a recent AIME math competition, beating Google Gemini’s 39 and ChatGPT’s 9. It also achieved a high 75% on a graduate-level reasoning (GPQA) test. These results suggest Grok 3 currently leads on pure complex reasoning puzzles. However, benchmarks only tell part of the story. In overall capability, Claude holds some advantages: it has a much larger context window and can ingest documents (Grok 3 initially couldn’t directly read long documents or PDFs). Claude is also generally stronger in generating nuanced, human-like text (Grok can be a bit more terse or technical). In a head-to-head review by Decrypt, Claude 3.5 Sonnet was considered the “gold standard” for creative writing quality – until Grok-3 surprised testers by slightly outperforming Claude on a very complex story-writing task. Grok’s story had better world-building and character depth, whereas Claude’s was technically coherent but a bit safe. This shows that the gap is closing even in Claude’s strongest domain (natural storytelling), but Claude was the benchmark to beat. With 3.7’s improvements, especially in “frontier performance” and content generation, it may reclaim some crown – but as of now, Grok 3 and Claude 3.7 are likely quite close, each with slight edges in different areas (Grok for hardcore logic and integrated web search, Claude for writing quality and coding). Both are considered among the most advanced AI models available.
Comparisons to Google Gemini and Others
Google’s Gemini (notably the Gemini 2 Pro model) is another rival in this space. Gemini integrates deeply with Google’s ecosystem and excels at real-time information access and integration with tools like searc. It’s very strong at tasks like looking up current information or working with Google Docs/Sheets. However, its pure reasoning capabilities are reported to be “not as strong as Grok 3’s” and presumably slightly behind Claude’s in some areas – Google is rapidly improving it, but in early tests Gemini has not yet matched Claude or GPT-4 on some academic benchmarks. Another emerging player is DeepSeek R1, a model developed on a smaller budget that nonetheless “outperforms ChatGPT and Claude in certain problem-solving tasks”, especially logic puzzles, though it’s less polished in generating long-form text. In practice, ChatGPT (GPT-4) remains the most widely used AI by general users and is very versatile – it’s excellent across many tasks and has handy features like integrated image generation (DALL·E 3). Yet, recent evaluations indicate that for complex reasoning or coding, Claude 3 and peers like Grok are edging ahead. Each model has its niche: ChatGPT for broad usability and creativity, Grok for rigorous reasoning and integrated research, Claude for elegant writing and balanced intelligence, Gemini for live info and tool use, etc.
In summary, Claude 3.7 Sonnet stands as one of the top-performing AI models in the world as of early 2025. It beats or matches leading models on key benchmarks for coding, reasoning, and knowledge tasks. Its hybrid chain-of-thought mode and massive context give it a unique practical edge over models like standard GPT-4. While competitors like OpenAI’s GPT-4, xAI’s Grok-3, and Google’s Gemini each have their strengths, Claude 3.7 is often the preferred choice when a natural, human-like response style and integrated reasoning are needed together. It effectively bridges the gap between fast chat and deep thought, which is a significant innovation in AI model design. Future head-to-head evaluations will no doubt continue, but Claude 3.7 has firmly secured its place among the AI leaders.
Use Cases and Real-World Applications
Claude 3.7 Sonnet’s versatility opens it up to a wide range of use cases across different industries. Thanks to its blend of rapid response and advanced reasoning, it can be applied in scenarios that demand both efficiency and intelligence. Below are some prominent use cases and real-world application examples:
Customer Support and Service
Claude’s highly human-like conversational style and large context window make it ideal for customer service chatbots and virtual assistants. It can handle long chat histories, understand follow-up questions, and provide empathetic, coherent answers. Many companies are integrating Claude into their support flows to automate customer Q&A, troubleshoot issues, or provide product information. Anthropic notes that customer-facing AI agents are a primary target for Claude 3.7, given its balance of speed and quality. For example, an e-commerce company could deploy Claude to handle live chat inquiries, where it can instantly answer simple questions in standard mode, but also dive into policy details or perform account troubleshooting in extended mode when needed. Its ability to produce “natural, human-like writing” means customer interactions feel more genuine and less robotic – a big plus in support contexts.
Knowledge Management and Research
With a 200k-token memory, Claude 3.7 can ingest and analyze very large knowledge bases, documents, or literature. This makes it a powerful research assistant in fields like law, academia, and consulting. It can perform document summarization, extract key points from lengthy reports, and even compare and synthesize information from multiple sources. Researchers can feed in entire PDFs or datasets and ask Claude for summaries, insights, or to answer questions based on the materials. For instance, in one test an earlier Claude model was able to read a 47-page IMF report (over 32K tokens) and summarize it, something that caused other models to crash. Enterprises are using Claude for knowledge retrieval (RAG – Retrieval-Augmented Generation) scenarios, where Claude serves as a natural language interface to company data. Anthropic specifically lists “RAG or search & retrieval over vast amounts of knowledge” as a supported use case for Claude 3.7. This is already happening via integrations like the one with Box and Amazon Bedrock (allowing corporate documents in Box to be queried via Claude). In R&D departments, Claude can assist in literature reviews, brainstorming hypotheses, or summarizing the latest findings – essentially acting as a tireless analyst that can read hundreds of pages in seconds.
Token capacity is a ceiling, not a default. We rarely “max out” the 200k window on Claude Sonnet 3.7 unless we’re running document summarization or multi-agent chaining where long-term memory is essential. For most AI ops—RAG-based customer service, sales scripts, or code reviews—we aim to stay under 30k tokens per call. Token costs add up faster than most realize, so we use programmatic scoring to decide whether a prompt needs that depth. The best ROI comes from pairing high-context models with token discipline, not token abundance.
– Daniel Lynch, Digital Agency Owner, Empathy First Media
Software Development and IT
Given Claude 3.7’s coding improvements, it is being used extensively in software engineering workflows. Developers can leverage it for code generation, getting boilerplate or even complex functions written based on natural language specs. Claude can also perform code review and debugging: a developer can paste an error trace or a piece of code and ask Claude to find the bug or suggest fixes. Its extended reasoning is beneficial here – it can step through the code logic methodically. The model’s understanding of large code contexts (entire repositories) means it can handle enterprise-scale codebases. Companies like Replit and Cursor have integrated Claude to assist programmers in real time. One real-world example: Replit’s Ghostwriter AI pair programmer now uses Claude to let users describe an app they want, and Claude will generate the multi-file project (frontend, backend, etc.) – Replit engineers reported Claude 3.7 could build working web apps from scratch where other models got stuck. Claude is also helpful in DevOps tasks; for instance, with the Claude Code CLI, a developer can instruct Claude to run tests, update configurations, or parse log files to identify issues. In summary, from writing code to troubleshooting to documentation generation, Claude acts as a skilled junior developer or assistant, accelerating software development cycles.
Content Creation and Marketing
Many users turn to Claude for generating written content – be it marketing copy, articles, social media posts, or even creative writing. Claude’s writing style is particularly prized for being coherent and contextually aware. It was previously considered the top AI for creative storytelling and narrative writing, and remains a strong choice for any creative content tasks. For example, a marketing team might use Claude to generate several variations of product descriptions or ad copy targeting different audiences, leveraging its nuanced language abilities. It can take a terse bullet list of features and expand it into a polished, engaging paragraph. In the publishing and media industry, editors use Claude to assist with drafting blog posts, press releases, or video scripts. Its extended mode can even be used to brainstorm – e.g., asking Claude to think step-by-step to come up with campaign ideas or plot outlines. Users often comment that Claude’s outputs “read more like a human wrote it” compared to other AI, capturing tone and style effectively. This makes it valuable for content that needs a personal or creative touch. Additionally, Claude can produce richly formatted text (including Markup/HTML), which is useful for drafting emails, slides, or formatted reports directly.
Financial Services and Analysis
In finance, Claude can digest large financial reports, spreadsheets, or market data and provide summaries or answer questions. Its ability to do math with reasoning steps helps in analyzing numerical data or performing scenario analysis. Some fintech startups are using Claude as a financial advisor chatbot or analyst assistant. For instance, one developer built a personalized financial advisor using Claude 3.5 Sonnet to help answer investment questions and plan budgets. Claude can parse through SEC filings or earnings call transcripts and highlight red flags or key points for analysts. In banking, it could assist customer reps by instantly pulling relevant info from complex policy documents or regulatory texts when a client asks a detailed question. The combination of quick recall (from its training knowledge) and deep reasoning means it can handle technical finance queries that require both factual accuracy and logical calculation.
Healthcare and Medicine
While not a doctor, Claude 3.7 can be used to analyze medical literature, summarize patient guidelines, or assist with medical coding and documentation. Its large context window could, for example, intake a patient’s medical history and a draft clinical note and help a physician write a concise summary or check for consistency. Researchers might use Claude to review large sets of clinical trial data or medical papers. (Of course, any medical use is accompanied by human validation due to the high stakes.) The model’s safety tuning likely makes it cautious in this domain, but its reasoning ability can help in evaluating diagnostic possibilities or explaining medical information in layman’s terms for patient-facing apps.
Business Analytics and Decision Support
Claude can serve as a business analyst by crunching through reports and data summaries. For instance, a sales team could feed in last quarter’s sales transcripts and CRM notes, and ask Claude to extract common customer pain points or product feedback themes. In project management, Claude can read through status updates or design documents and produce a distilled brief for executives. Its use cases in forecasting and marketing are explicitly noted by Anthropic – e.g., generating sales forecasts or analyzing marketing campaign results. Claude could examine a dataset of sales numbers and marketing spend (converted to a textual table or CSV input) and then output insights or regression analysis in plain English. It essentially can act like a data consultant, given the data in textual form.
Education and Training
As a tutoring tool, Claude 3.7 can help explain complex concepts step-by-step (leveraging its chain-of-thought ability). Students can ask it to break down difficult problems, and it will not only give the answer but also the reasoning process in extended mode, which is great for learning. It can generate practice questions, check answers, and even act as a debate opponent or conversational partner in language learning. Its safer alignment (fewer inappropriate outputs) makes it a candidate for educational settings. Some educators use Claude to draft lesson plans or to simplify academic texts for different grade levels. With its large memory, it could consume an entire textbook and answer nuanced questions from it, functioning as a personalized tutor.
These examples only scratch the surface. Across industries – from tech to finance to healthcare to customer service – Claude 3.7 is being applied wherever complex language tasks are present. Its ability to both “answer normally” and “think deeply” on command means it adapts well to varied workflows. For quick tasks like translations or FAQs, it’s as snappy as needed (Claude 3 Haiku, a faster sibling model, covers ultra-quick jobs too). For heavy-duty tasks like strategic planning or debugging or research analysis, Claude can slow down and deliver thought-out responses. Businesses are also drawn to its integration on platforms like Amazon Bedrock and Google Cloud Vertex AI, making it easier to deploy within enterprise applications. From all indications, early adopters have found that Claude 3.7 greatly accelerates and enhances tasks that used to require significant human effort – whether it’s writing a detailed report or sifting through a knowledge base or generating code, Claude is augmenting human work across the board.
User Experiences and Testimonials
The reception to Claude 3’s “Sonnet” series has been very positive, and version 3.7 in particular is earning praise for its improvements. Users ranging from individual developers to enterprise teams have shared their experiences. Here are some perspectives and testimonials from different sources:
Developers on Claude’s Coding Skills
Many developers have been impressed by Claude’s programming assistance. One programmer compared Claude 3.5 Sonnet to OpenAI’s GPT-4 and concluded that “Claude 3.5 Sonnet has impressed me with its coding prowess, accurate summarization, and natural communication style.” This reflects common feedback that Claude writes code well and also explains it clearly. With Claude 3.7’s further gains in coding, early users report it’s even better at handling complex coding queries. As noted, internal tests by tools like Cursor and Replit showed Claude outperforming other models on real coding tasks, which suggests that developers using it in day-to-day work find it more reliable for code generation and debugging. The introduction of Claude Code (the CLI agent) has also been received enthusiastically by beta users – Anthropic’s team itself said Claude Code became “indispensable” for them during internal testing, doing 45-minute coding tasks in one go. This kind of result has generated excitement among engineers who dream of automating tedious programming chores. On forums, users have started sharing success stories of building entire small apps with minimal coding by hand – instead, they delegate to Claude and get solid results.
Content Creators and Writers
Users who utilize AI for writing often comment on Claude’s natural tone. It tends to produce less stilted prose than some other models. A tech review by Fello AI noted “Claude… is known for producing the most natural, human-like writing of any AI model.” In side-by-side blog post generations, writers found Claude’s style engaging and coherent, often requiring fewer edits for tone. One comparison said Claude’s articles “read more like a human-written piece – incorporating humor, clear explanations, and natural language that resonates with readers.” . This human-like quality is a big plus for creative professionals. Testimonials from marketers mention that Claude is good at capturing brand voice when given a few examples. It also handles instructions like “make it friendlier” or “add a touch of humor” very deftly. Users appreciate that they can get long-form content that doesn’t sound robotic. Even in creative writing, where GPT-4 was strong, Claude is often equally good; a Decrypt review noted Claude 3.5 was previously the “gold standard” in creative tasks until one instance where Grok-3 edged it out – meaning Claude was effectively considered the benchmark for quality creative outputs. With 3.7’s enhancements, many expect it to continue delighting writers and content creators. On social media, some authors have shared how they use Claude to overcome writer’s block: “I let Claude brainstorm plot points, and it gave me better ideas than I had myself,” one novelist tweeted (anecdotally).
Enterprise and Professional Feedback
Enterprise users have been trialing Claude 3.7 through the Claude.ai platform and API. A common theme in feedback is simplicity and integration. Anthropic’s Chief Product Officer, Mike Krieger (co-founder of Instagram), noted that the hybrid approach simplifies things for customers – they no longer have to decide which model or mode to use for a given task, Claude just adapts. This resonates with business users who don’t want to juggle multiple AI services. Early adopters in companies like Canva, Vercel, etc., provided feedback during testing (as quoted earlier) which essentially serve as testimonials to Claude’s value: e.g. Canva’s tech team saw higher quality outputs and fewer errors in code generation than before, which for them means faster feature development. Another piece of user feedback came from internal evaluations at an AI safety firm “Cognition,” which found Claude’s planning and reasoning in coding tasks significantly better than other models – a strong endorsement for those who need an AI that can think through problems systematically. On the Reddit forum r/ClaudeAI, users have been excitedly discussing the 3.7 release, with one user commenting that even with the same base model size, “the improvements in 3.7 are very noticeable – it’s like the model has better common sense and doesn’t get stuck as often.” (This aligns with Anthropic’s claim of focusing training on real-world task reliability).
Oh, tackling huge chunks of data like 100k+ tokens definitely poses a big challenge. From what I’ve gathered, systems like Claude Sonnet 3.7 tend to use a mix of techniques to manage such heavy loads. They might compress data to reduce the size and speed up processing. Also, segmenting the data into more manageable parts often proves super helpful. This way, each segment can be processed more efficiently without causing the system to get overwhelmed.
– Alex Cornici, Marketing & PR Coordinator, Insuranks
General Users (Chatbot Experience)
Everyday users of the free Claude chat (who use it as an alternative to ChatGPT) have noted a few improvements with Claude 3.7. First, it’s less likely to give an unwanted refusal. Earlier Claude versions had a reputation for sometimes refusing queries that weren’t truly disallowed (being overly cautious). Anthropic addressed this, reporting a 45% reduction in unnecessary refusals in Claude 3.7 compared to its predecessor. Users indeed confirm they can ask a wider range of questions without hitting a dead-end response. Second, users report that Claude’s responses feel more accurate and to-the-point. Thanks to extended reasoning, when enabled, it makes fewer simple mistakes on things like math word problems or tricky logic questions. One user gave the example: “Claude 3.7 correctly solved a multi-step riddle that Claude 2 and 3.5 kept getting wrong.” Many casual users also enjoy the visible reasoning feature – some have said it’s like watching the AI “show its work,” which not only builds trust but is educational. “It’s like the AI is thinking out loud, and I can follow along,” one user wrote, “which helps me understand the answer better.” However, some users also jokingly said watching the chain-of-thought can be like seeing how the sausage gets made – interesting but sometimes verbose. Fortunately, you can turn it off if you just want the final answer.
Safety and Trust
On the question of model safety and alignment, expert users and AI ethicists have been examining Claude 3.7 as well. Anthropic has a reputation for prioritizing AI safety, and some user testers have pushed Claude’s limits to see how it responds. The consensus is that Claude 3.7 is significantly harder to jailbreak or provoke into bad behavior than many models before. In fact, Anthropic launched a “red-teaming” challenge with earlier Claude versions offering $20k to anyone who could jailbreak it, and very few succeeded. With 3.7’s updated safety training (using something Anthropic calls Constitutional AI and new classifier defenses), users are finding it rarely produces disallowed content. One Reddit user attempting jailbreaking said Claude “has a moral crisis when jailbreak prompts leak the system instructions” and it refuses to continue – showing the guardrails kicking in. While general users might not notice this directly, it means the average experience is that Claude stays on track and doesn’t veer into problematic outputs often. That said, some power users do note that Claude can still be more cautious than ChatGPT on certain borderline queries (e.g. medical or legal advice, or explicit content), but the nuance of its refusals has improved – it will explain its reasoning or partially comply if it can, rather than a flat “no.” Overall, user trust in Claude seems high, owing to its transparent reasoning and Anthropic’s safety efforts.
In aggregate, user experience with Claude 3.7 Sonnet has been very favorable. Users frequently cite its clarity, coherence, and intelligence in responses as major positives. It’s often described as feeling more like “talking to a knowledgeable colleague” rather than a bot. There are, of course, areas to improve (it’s not perfect – see limitations), but the testimonials indicate that Anthropic’s newest model is delivering on its promises for a lot of people. Many who have tried multiple AI assistants now keep Claude in their toolkit, if not as their primary assistant. Especially for those who need a mix of fast answers and deep reasoning (students, developers, analysts, writers), Claude 3.7 has quickly become a go-to AI tool.
Pricing, Availability, and Adoption
Claude 3.7 Sonnet is broadly available through multiple channels, with a pricing model designed to be accessible for both individual users and enterprises. Below is an overview of how Claude 3.7 is being offered and adopted:
Pricing Model
Anthropic has kept pricing constant for Claude 3.7 Sonnet, in line with previous Claude versions. The API pricing is $3 per million input tokens and $15 per million output tokens. This pricing includes any “thinking” tokens used in extended reasoning – in other words, if Claude uses 10,000 tokens to internally reason and produces a 1,000-token answer, only 11,000 output tokens are billed. To put the cost in perspective, $15 per million tokens equates to $0.015 per 1,000 tokens, which is quite affordable (for comparison, OpenAI’s GPT-4 API is roughly $0.06 per 1,000 tokens for outputs, four times higher). Anthropic emphasizes that Claude 3’s Sonnet tier is more affordable than other models of similar intelligence. This is part of their strategy to encourage scale – large deployments and usage volumes – by lowering the cost barrier. There are higher-tier models (Claude 3 Opus) that are more expensive (Opus costs $15 per million input, $75 per million output), but those are aimed at specialized needs. The Claude 3.7 Sonnet tier provides a strong performance-to-cost balance; at $3/$15 per million tokens, it significantly undercuts many competitors’ flagship models on price. For end users, Claude.ai offers a free tier and a Pro subscription: as of now, the free tier allows unlimited usage of Claude 3.7 Sonnet (with some rate limits and without the extended reasoning mode), while Claude Pro (paid at around $20/month) gives priority access, the ability to use Claude 3.7’s extended mode in chat, and access to Claude 3 Opus for even higher quality on demand. This freemium model has helped spread adoption by letting people try Claude at no cost and then upgrade if they need more. Here’s what experts have to say about pricing:
My data shows token budgets are typically 60-70% underused in the first 90 days, then swing to 120-130% of projected spend as teams find real value cases. The sweet spot emerges around month 4-5 when companies balance cost-effective usage with high-impact applications. Setting clear token budgets by department based on potential ROI is essential for avoiding costly overruns.
– Ryan T. Murphy, Sales Operations Manager, Upfront Operations
Availability and Platforms
Claude 3.7 is immediately available across Anthropic’s own products and partner services. On Claude.ai (the web interface) – which is open globally – Claude 3.7 Sonnet is powering all user conversations by default. Free users get Claude 3.7 in standard mode, while Pro users can toggle extended thinking or switch to Claude 3.7’s big brother (Opus) for certain prompts. For developers and companies, the Claude API is the main access point. Anthropic’s API for Claude is generally available in 159 countries as of 2024, meaning developers worldwide can sign up and integrate Claude into their apps. Importantly, Claude 3.7 Sonnet is also offered through Amazon Bedrock and Google Cloud Vertex AI. Amazon Bedrock (AWS’s AI model hosting service) has Claude 3.7 Sonnet live now, thanks to Amazon’s partnership and investment in Anthropic. This allows AWS customers to deploy Claude in their cloud workflows easily. Google’s Vertex AI Model Garden has Claude 3 in private preview (Sonnet available now, with Opus to come) – Google is also an investor in Anthropic, which paves the way for tight integration there. These cloud partnerships greatly enhance Claude’s availability to enterprises; a company using AWS or GCP can select Claude 3.7 via those platforms with a few clicks, rather than setting up separate infrastructure. In addition, several AI products and startups have built Claude in: for example, perplexity.ai (a popular AI search engine) uses Claude on the backend for some of its answers, and tools like Fello AI’s Mac clients list Claude as an option. Overall, Claude 3.7 is not hard to access – whether you’re an individual user via a web browser or a developer via API or a large enterprise via AWS/GCP, the model is readily reachable.
Adoption Trends
The user base of Claude has grown rapidly since the Claude 3 family launched in 2024, and the 3.7 release is expected to accelerate that growth. Anthropic’s co-founder Jared Kaplan mentioned they “see exploding demand that’s hard to keep up with” for their models, with usage climbing as the models get smarter and more capable. The free Claude.ai service has attracted many users (likely in the millions, given its open availability and the allure of a free 100k+ context chatbot). It’s often touted as a top alternative to ChatGPT, which has driven organic adoption among AI enthusiasts and professionals alike. On the enterprise side, Anthropic’s deep partnership with Amazon is a big factor in adoption. In 2023, Amazon committed $4 billion to Anthropic, and by 2024 it had invested $8 billion total into Anthropic’s efforts – in return, Anthropic agreed to make Claude available first-class on AWS. This has led to many AWS customers piloting Claude for various purposes (from Fortune 500 companies to startups on Amazon’s cloud). Similarly, Google’s expected $2B investment (reportedly in talks) indicates that Google Cloud’s clientele will also be adopting Claude in their workflows. We are seeing Claude being used in production by companies in sectors like finance (for analytical chatbots), e-commerce (for customer service and product recommendation bots), and SaaS companies (adding AI assistants within their software). For example, through Amazon Bedrock, enterprise software company Box announced integration of Claude to help summarize and query documents stored in Box for its customers. This kind of integration brings Claude to potentially tens of thousands of end-users in a business context without them even knowing it’s Claude under the hood.
Adoption vs. Competitors
In terms of market adoption, OpenAI’s ChatGPT still has the largest mindshare (hundreds of millions of users via the ChatGPT app). However, Claude is carving out a strong presence, especially among professional and developer communities who value its features. One indicator: on coding Q&A sites and AI forums, more users are sharing Claude prompts and results, not just ChatGPT’s. Another is third-party client support: apps that let you use AI from your phone or desktop have started including Claude alongside GPT-4 (as seen with Fello AI’s clients offering GPT-4, Claude 3.5, Gemini, etc., in one interface). This shows that power users want access to Claude’s capabilities in addition to OpenAI’s. In enterprise adoption, the landscape is still forming, but Anthropic’s big valuation (recent funding talks valued it at ~$60B) and backing from Big Tech suggest that many enterprise clients will at least trial Claude as a safer or more flexible alternative to OpenAI. There’s also specialization: organizations that specifically need huge context windows or who prioritize transparency in reasoning might choose Claude 3.7 for those reasons. On the flip side, some smaller companies or individuals might be drawn to OpenAI’s lower-end models or open-source alternatives for cost reasons (since Claude, while cheaper than GPT-4, is not as cheap as open models or OpenAI’s smaller offerings). Anthropic’s move to not raise prices for 3.7 indicates they are keen on wider adoption and not squeezing users on cost, which is being well-received.
In summary, Claude 3.7 Sonnet is widely accessible and competitively priced. Its presence on major cloud platforms and a free web version lowers the friction for adoption significantly. Early data and anecdotes point to a growing user community and increasing enterprise uptake. Anthropic’s strategic partnerships (Amazon, Google) are positioning Claude as a standard AI service within those ecosystems. If these trends continue, Claude could see very broad adoption, potentially becoming as ubiquitous in business settings as ChatGPT is in consumer settings. Anthropic’s focus on reliability and safety also makes Claude appealing to organizations that require trustworthiness from AI – an adoption driver as AI systems become more deeply integrated into workflows.
Recent Updates, Improvements, and Controversies
Claude 3.7 Sonnet, being a fresh release, comes with several updates and improvements over previous versions. It has also spurred some discussion (and a bit of controversy) in the AI community. Here we outline the latest developments and any notable debates around Claude 3.7:
The reasoning features absolutely consume credits at a seriously dramatically faster rate than the old Claude 3.5, sometimes they’re approaching $1 per substantial edit, which becomes really prohibitively expensive at our production volumes without dedicated budget allocations. For most of our content generation needs, the standard model without reasoning provides sufficient quality, with reasoning capabilities reserved only for complex technical content requiring specialized knowledge synthesis or advanced research capabilities.
– Sandy Meier, Head of Marketing, Contentellect
Latest Updates in Claude 3.7
The major update, of course, is the introduction of the extended thinking (hybrid reasoning) mode. This is a new capability that was not present in Claude 2 or the initial Claude 3 releases. Anthropic rolled this out in 3.7 as a result of research indicating that letting the model deliberate improves outcomes. Another recent update bundled with 3.7 is Claude Code, the agentic coding assistant (as a research preview). While Claude Code is a separate tool, it’s part of the Claude 3.7 launch and shows Anthropic’s direction of adding more agent features. Additionally, Anthropic improved Claude’s performance in areas like math, science, and coding by fine-tuning on more real-world examples instead of just competition benchmarks. On the user side, the Claude.ai interface was updated to allow toggling “Extended Thinking” mode for Claude 3.7 (for paid users) and to integrate the GitHub repo connection for coding tasks. All these enhancements were delivered at launch. Anthropic also published a detailed system card for Claude 3.7, highlighting its safety evaluations and how it handles things like prompt injections, reflecting transparency about what changed under the hood. As a minor update, Anthropic addressed some naming confusion: internally, they initially labeled versions like “Claude 3.5” and “Claude 3.7” with codenames (like “Haiku”, “Sonnet”, “Opus”). The 3.7 name itself is interesting – many expected this upgrade to be called “Claude 4”, but Anthropic opted for 3.7 to indicate an incremental improvement rather than a full generation leap. This aligns with OpenAI’s strategy (they’re moving to GPT-4.5 rather than GPT-5). So essentially, Anthropic delivered a significant feature upgrade without branding it a new numbered version.
Improvements Over Previous Versions
Compared to Claude 3.5 (the last major Sonnet release), users and Anthropic report notable improvements. The model’s reasoning ability is stronger – it can solve problems now that stumped it before, thanks to the chain-of-thought capability. It’s also more consistent in following instructions for complex tasks. The reduction in overzealous refusals (45% fewer unnecessary refusals) means a smoother experience for users who found Claude 2/3 would sometimes abruptly decline requests. This suggests the model now better distinguishes truly disallowed content from benign requests that just happen to touch sensitive topics. Anthropic also claims Claude 3.7 makes more nuanced judgments on potentially harmful queries (likely an outcome of retraining with feedback). Another improvement is in multimodal handling – Claude was already good at processing images/PDFs, but extended mode means it can analyze them more deeply. For example, it can take a chart image and not just describe it, but reason about what the chart implies if asked. The context handling might also be more efficient; though 200k was available in Claude 3, some users noted slowdowns with huge inputs – Claude 3.7’s code optimizations (under the hood) aim to make large context usage more practical. Anthropic’s blog indicated that they’ve optimized the model on “real-world tasks” and adjusted its focus away from just academic puzzles, which should make it more robust in business applications. We’ve also seen improvement in speed: Sonnet models are generally faster than the previous gen (Claude 2). Claude 3.7 in standard mode can output answers nearly instantly for short prompts, and even in extended mode, it’s fairly efficient given what it’s doing. Users who have tried it side by side with 3.5 report slightly faster responses and less latency variability.
Controversies and Debates
With any powerful AI model release, there’s bound to be discussion about its impact. Claude 3.7 is no exception, though there haven’t been any major scandals or failures – the controversies are more on the philosophical/policy side:
- AI Safety and “AI Race” Concerns: Anthropic’s release of Claude 3 (and now 3.7) has stirred debate in the AI safety community about whether pushing out increasingly advanced models is a net positive or negative. Some AI safety experts worry that each new state-of-the-art model from companies like Anthropic or OpenAI contributes to a competitive dynamic (“arms race”) that could incentivize rushing and cutting corners on safety. In fact, on the Effective Altruism forum, a discussion titled “Was Releasing Claude-3 Net-Negative?” took place, exploring if Anthropic’s release might pressure others to speed up at the expense of thorough testing. The argument is that if Anthropic holds back, perhaps OpenAI and others would also pause to evaluate more, whereas releasing Claude 3 possibly intensified competition. However, Anthropic’s leadership has a counter-view: they believe being at the frontier helps them set a positive example and influence the trajectory of AI. Dario Amodei (Anthropic’s CEO) and others have argued that deploying advanced models with strong safety measures is better than ceding ground to possibly less cautious actors. Indeed, Anthropic’s work on things like constitutional AI has somewhat raised the bar for safety among frontier models. This debate is ongoing, and Claude 3.7’s launch inevitably feeds into it – though 3.7 is an incremental update, it still ups the capability ante.
- Lack of Internet Access: Leading up to this release, there were rumors (even “leaks”) that Claude might get web browsing or internet search capabilities (similar to how ChatGPT has a browsing mode). The leaked AWS Bedrock description we saw focused on reasoning mode and did not mention internet access. Indeed, the released Claude 3.7 does not have built-in web browsing. Some users expressed disappointment because they anticipated a ChatGPT+WebGPT equivalent. BGR noted “the Claude 3.7 description doesn’t mention internet search” and that this was an interesting twist, given the CEO had teased future “internet search support” earlier. This isn’t a controversy per se, but it’s a notable missing feature that people discussed. It’s possible Anthropic is holding off on that until a later “Claude 4” update, or focusing on partnerships (e.g., via Bing or Google integration) rather than building their own browser. For now, users who need up-to-date info still have to provide it to Claude or use a separate tool.
- Name and Versioning: As mentioned, calling it Claude 3.7 instead of 4 raised some eyebrows. While most understood the reasoning (not a full next-gen jump), a few commentators joked that Anthropic was being conservative with version numbers. There were also some early confusion in documentation where it was referred to as “Claude 3.7 (20250219 v1.0)” in internal notes – but that’s mostly trivial. Ultimately, the naming “Sonnet” for the mid-tier model and these decimal versions reflect Anthropic’s practice of continuous improvement.
- Anthropic’s Funding and Big Tech Influence: Outside the technical realm, there’s been significant news around Anthropic itself – e.g., the company in talks to raise another $2 billion with a valuation of $60 billion. Some industry watchers have voiced concern that Anthropic’s heavy funding from Big Tech (Amazon and potentially Google) might influence its openness or direction. For instance, Amazon having a stake might prioritize AWS integration (which has happened) and could give Amazon a lot of influence over Anthropic’s customer relationships. To date, there’s no public controversy here, but it’s a development to watch as Claude’s ecosystem grows.
- Missteps or Bugs: Since Claude 3.7 is very new, there haven’t been widely reported bugs or incidents. No “Tay-style” mishaps or glaring failures in the wild. If anything, the community has been actively trying to jailbreak or break it and mostly finding it quite robust. One minor issue some users noticed: in the first days, the Claude extended mode UI sometimes showed the chain-of-thought with a slight delay or required re-sending the prompt – likely launch kinks that got ironed out. This was more of a technical hiccup than a controversy.
Overall, Claude 3.7’s release has been smooth and positively received, with few controversies. The main discussions around it center on Anthropic’s approach of rolling out powerful features carefully and what that means for the competitive landscape. Anthropic has been transparent about improvements (through system cards and blog posts) and proactive in addressing concerns (e.g., highlighting how they test for prompt injection attacks, and inviting external audits). If any controversy does emerge, it might be if someone finds a way to misuse the new agentic capabilities – but the company’s “limited preview” approach for Claude Code suggests they are mitigating that by controlling access and learning from a small user base first. In summary, the conversation around Claude 3.7 is far more about its capabilities and promise than any negative fallout. It’s seen as a bold step forward (hybrid reasoning in one model) taken in a responsible manner.
Strengths and Limitations
Claude 3.7 Sonnet brings a host of strengths that make it one of the leading AI models, but it also has certain limitations and areas where users need to be mindful. Here we provide a balanced summary of its key strengths and its current limitations, supported by quotes from experts:
Strengths
Hybrid Reasoning Flexibility
Claude’s most distinctive strength is its hybrid fast/deep reasoning ability. Users can get near-instant answers or more deliberative, high-quality answers from the same model. This flexibility is unmatched by others at the moment and means Claude can handle both trivial queries and extremely complex ones adeptly. It’s like having two AI specialists in one – a quick responder and a careful problem solver.
Extremely Large Context Window
With support for ~200K tokens of context, Claude can take in enormous amounts of information at once. This is a huge advantage for tasks like analyzing long documents, multi-document analysis, or maintaining very long conversations without losing context. Many competitor models max out at 32K or 100K tokens. Claude’s 200K context is currently one of the largest available in any public model, letting it handle tasks others simply cannot due to input length limitations. This makes it ideal for enterprises dealing with big data and knowledge bases.
Natural, Human-like Language Generation
Claude consistently produces outputs that are fluent, coherent, and often indistinguishable from something a human might write in tone and style. It particularly shines in writing tasks – whether it’s creative storytelling, explanatory essays, or professional emails, its responses tend to be well-structured and nuanced. Independent reviewers have noted that Claude’s writing is the most “human-like” among AI models and that it resonates well with readers by incorporating context appropriately. This is a major strength when the goal is to create content that engages or to communicate complex ideas clearly.
Advanced Coding and Tool Use
Claude 3.7 is arguably state-of-the-art in coding assistance. It has demonstrated best-in-class performance on real-world coding benchmarks and earned praise for handling complex programming tasks where others falter. Its capability to use tools (like running code, using a terminal, searching within files) as seen in Claude Code preview, and even without that, its adeptness at understanding instructions to call APIs or format outputs for external systems, make it extremely powerful for developers. In practical terms, it can save developers significant time by writing boilerplate code, finding bugs, and integrating with dev workflows – effectively serving as a diligent coding companion.
Strong Reasoning and Accuracy (with Extended Mode)
When using its chain-of-thought mode, Claude’s accuracy on complex reasoning tasks jumps noticeably. It can solve math word problems, logic puzzles, or multi-step analytical questions much more reliably than when it must answer immediately. This extended reasoning helps reduce errors in domains where intermediate reasoning is needed. Claude’s performance on benchmarks like math (GSM8K) and logical reasoning tasks is among the top, thanks to this capability.It also has improved factual accuracy in scenarios like coding or step-by-step instructions, because it “double-checks” itself in extended mode. Anthropic’s focus on real-world task training (instead of just puzzle benchmarks) also means it’s less likely to be tripped up by ambiguous queries – it uses common sense better.Plus, it handles ambiguity in code navigation decently.
Recently, I was refactoring a messy React codebase with multiple formatDate() functions across different utility files. Instead of assuming, Claude flagged the conflict and asked, “I see three versions—should we use the one from utils/date.js, helpers/display.js, or lib/time-utils.js?” That’s the sweet spot: smart enough to narrow things down but honest when it needs help. Other tools might silently pick the wrong function, but Claude’s balance of context awareness and clarity keeps mistakes from slipping through.
– Paul DeMott, Chief Technology Officer, Helium SEO
Transparency and Safety
Claude’s design allows it to be more transparent (by showing its reasoning), which can increase user trust. From a safety perspective, it is one of the most robust models against misuse. It is trained to make finer distinctions and not refuse arbitrarily, yet still hold firm on truly harmful requests. External evaluations have found Claude to have a good balance of compliance and caution – in one “over-refusal” safety benchmark, Claude models were noted to have the highest safety compliance while minimizing unnecessary refusals. For organizations, this strength means deploying Claude carries a bit less risk of wild, inappropriate outputs compared to some other models, which is important for brand and user safety.
Multimodal Understanding
Claude can handle text with images or diagrams (when provided via API or data URLs) and extract information or analyze them, which is a strength for use cases involving visual data. It can describe images, parse graphs, and even do OCR on text images. Not every model (besides say GPT-4 Vision or some Google models) can do this at Claude’s level. This adds to its versatility for businesses dealing with PDFs, scanned documents, etc. where the model can directly process these within the 200K context.
Integration and Ecosystem
Another strength is how well-integrated Claude is becoming on various platforms. Availability on AWS and GCP means it can slot into existing enterprise tech stacks easily. Its API is straightforward and compatible with typical AI developer workflows. Moreover, being part of a model family (Haiku, Sonnet, Opus) means users can choose a smaller or larger variant if needed, without leaving the ecosystem. This flexibility (e.g., using Haiku for speed and Sonnet for intelligence on the same platform) is a strategic strength when competing models might be one-size-fits-all.
Limitations
Claude could generate perfect schema code but couldn’t effectively troubleshoot implementation errors across CMS platforms, especially when conditional logic was needed based on API responses. For developers building complex systems, I recommend focusing Claude on the “thinking” tasks where judgment is needed – content creation, analysis, decision support – while using purpose-built tools for orchestration. This hybrid approach is how we’ve maintained those 40%+ response rates in our follow-up sequences while scaling across different verticals and technical environments.
– Raymond Strippy, Founder, Growth Catalyst Crew
Other limitations include:
Latency and Speed Trade-off
While Claude can respond quickly in normal mode, when using extended thinking mode for tough problems, responses naturally take longer. The model might spend several seconds (or more, depending on the token budget given) to “think” before producing a final answer. This is by design – complex reasoning needs time – but it means that for users expecting instant answers always, the extended mode can feel slow. In time-sensitive applications, one might have to stick to standard mode, sacrificing some quality. Essentially, Claude cannot defy the speed-quality trade-off; it just gives the user control over it. Competing models without an explicit “think mode” might respond faster (albeit with less reasoning). So, if a user enables extended thinking liberally, they must accept higher latency and token usage costs.
Lack of Native Internet/Browsing Capability
Unlike some versions of ChatGPT (which can browse the web) or xAI’s Grok (which has a “Deep Search” tool for real-time info), Claude 3.7 has no built-in internet access at this time. It works off its training data (knowledge cutoff late 2024) and whatever the user provides in the prompt. This means it can’t fetch real-time information or verify current events on its own. For use cases that require up-to-the-minute data (news analysis, live sports, stock prices, etc.), Claude is limited unless the user supplies that info. BGR highlighted that internet search wasn’t part of this update, and indeed, that’s a gap. Users needing that capability have to create a workaround (for example, using an external search API and feeding results to Claude). This puts Claude at a slight disadvantage in applications like investigative research or any task where on-demand lookup is required.
Potential for Hallucination and Errors
Claude, like all large language models, can still hallucinate – i.e., produce incorrect statements or fabricate information – especially if asked about obscure facts or if it “thinks” in extended mode without proper checking. While the chain-of-thought helps reduce simple mistakes, it’s not foolproof. For instance, in one third-party test, Claude hallucinated a quote from a document that wasn’t actually present, whereas a competitor (Grok) managed to avoid that. This shows that if Claude is confident about something that isn’t true, it may generate a plausible-sounding but false answer. Users must stay vigilant that Claude’s outputs are not guaranteed 100% correct. It still lacks a true ground truth verification mechanism. That said, its hallucination frequency is moderate and comparable to GPT-4’s, but any non-trivial use (especially in fields like law or medicine) will require human verification.
Overlong or Verbose Outputs
A minor gripe some users have noted is that Claude can be verbose, often erring on the side of providing very detailed answers. Sometimes a user just wants a concise response, but Claude might give a thorough explanation (it was trained to be helpful and comprehensive). This can require the user to prompt it to be brief or to edit down the output. It’s not a severe limitation – one can guide the style – but it contrasts with, say, OpenAI models, which by default often give somewhat shorter answers. Additionally, when chain-of-thought is visible, the full reasoning log can be lengthy (though this is only shown to the user, not in the final answer). So for quick interactions or when character count is a factor, Claude might need careful prompting to limit itself.
No Voice or Image Output (UI Limitations)
Currently, Claude’s interface and API deal with text in and text out (and accepting images as input in encoded form). It doesn’t natively produce images (no built-in DALL-E or image generation like some ChatGPT plugins allow), and it doesn’t have a voice interface of its own. This is a limitation for those who want a more multimedia AI experience. For instance, if a user wanted the AI to create an infographic or speak an answer aloud, they’d need external services. While not a core expectation of an LLM, competitors are bridging into multi-modal outputs (e.g., Bing Chat can display images or do text-to-speech in some clients). Claude stays focused on text, which in some scenarios is a limitation.
Still Closed Source and Cloud-Dependent
For organizations or individuals who prefer on-premise or open-source models for privacy or customization, Claude 3.7 is not an option in that sense. It’s a proprietary model that runs on Anthropic’s servers (or through partners). You cannot self-host Claude (due to its size and Anthropic’s policies). Some companies might have data governance concerns that make them hesitant to send sensitive data to a third-party API, even though Anthropic likely has provisions for privacy. While this isn’t unique to Claude (same is true for OpenAI GPT-4, etc.), it’s worth noting as a limitation to adoption in highly regulated contexts. Anthropic has enterprise offerings to mitigate this (like dedicated instances), but it’s not the same as an open model you can fine-tune yourself. So for specialized needs requiring model retraining or offline operation, Claude cannot be directly used.
Extreme Cases and Unknowns
Pushing Claude to its limits, there may be edge cases where it doesn’t perform as well. For example, extremely long conversations (approaching that 200k limit) might lead to it losing some earlier context despite the window, due to how attention mechanisms scale (there’s not a lot of real-world testing of the full 200k usage yet). Also, while Claude is very good at logical reasoning, some anecdotal reports suggest that for certain types of riddles or programming puzzles, Claude 3.7 can still get confused or produce an answer that sounds logical but is off. There are also tasks like delicate ethical dilemmas or highly nuanced opinion generation, where the AI might waffle or give a generic answer to stay safe. These could be seen as limitations depending on the use case (e.g., if one wanted a very bold creative take, Claude might be a tad conservative due to its safety tuning). However, these are not glaring weaknesses, just areas where it might not be dramatically better than others.
For developers approaching that complexity ceiling, I recommend using Sonnet as a specialized tool: have it generate deterministic data parsers, validate smaller discrete payloads, or write API interface code, but offload the true state machine and cross-step reliability to orchestrators like NetSuite SDF, Power Automate or custom Node backends. That way you preserve AI acceleration where human logic bottlenecks exist, but protect your workflows from silent fuzziness and side effect bleed between dependent calls.
– Louis Balla, VP of Sales & Partner, Nuage
In conclusion, Claude 3.7 Sonnet’s strengths clearly outweigh its limitations for most users. It offers an exceptional blend of capability, especially in its reasoning, context handling, and language quality. These strengths make it a top choice for many complex tasks. Its limitations are mostly inherent to current AI tech (possibility of errors without fact-checking, no live data, etc.) or by design trade-offs (slower when thinking more, etc.). Users and organizations considering Claude 3.7 should be aware of these limitations and plan around them – for instance, keep a human in the loop for critical factual tasks, and integrate external tools for real-time info if needed. By doing so, one can leverage Claude’s strengths fully while mitigating the downsides.
Overall, Claude 3.7 Sonnet emerges as a powerful, well-rounded AI assistant, pushing the envelope in reasoning while maintaining practicality. Its introduction marks a step toward AI systems that can adapt their thinking to the task at hand, which is a promising direction for the industry. As with any technology, it’s not perfect – but it’s a remarkable tool whose capabilities, when used appropriately, can greatly augment human productivity and creativity in numerous domains. The progress Anthropic has demonstrated with Claude 3.7 also bodes well for future updates (Claude 4 and beyond), which the community will be watching with great interest.