Sitemap Crawling in Data Spaces
Data Spaces let you automatically ingest website content from sitemap URLs without writing any custom crawler logic. This allows agents to perform semantic search across a site’s structure using standard sitemap formats.
How it works
When you add a sitemap URL to a Data Space, SmythOS:
- Fetches the sitemap XML from the specified URL
- Parses all listed URLs (including nested sitemaps)
- Crawls each page and extracts relevant content
- Indexes that content into the selected Data Space
- Makes it searchable using RAG Search
Setup Instructions
Step 1: Create a Data Space
Follow the standard instructions in the Data Spaces guide to create a new container.
Step 2: Add a sitemap URL
- Open your Data Space
- Click Add Data Source
- Enter a suitable name for the data source as this is mandatory
- Enter your sitemap URL (e.g.,
https://example.com/sitemap.xml) in the last field
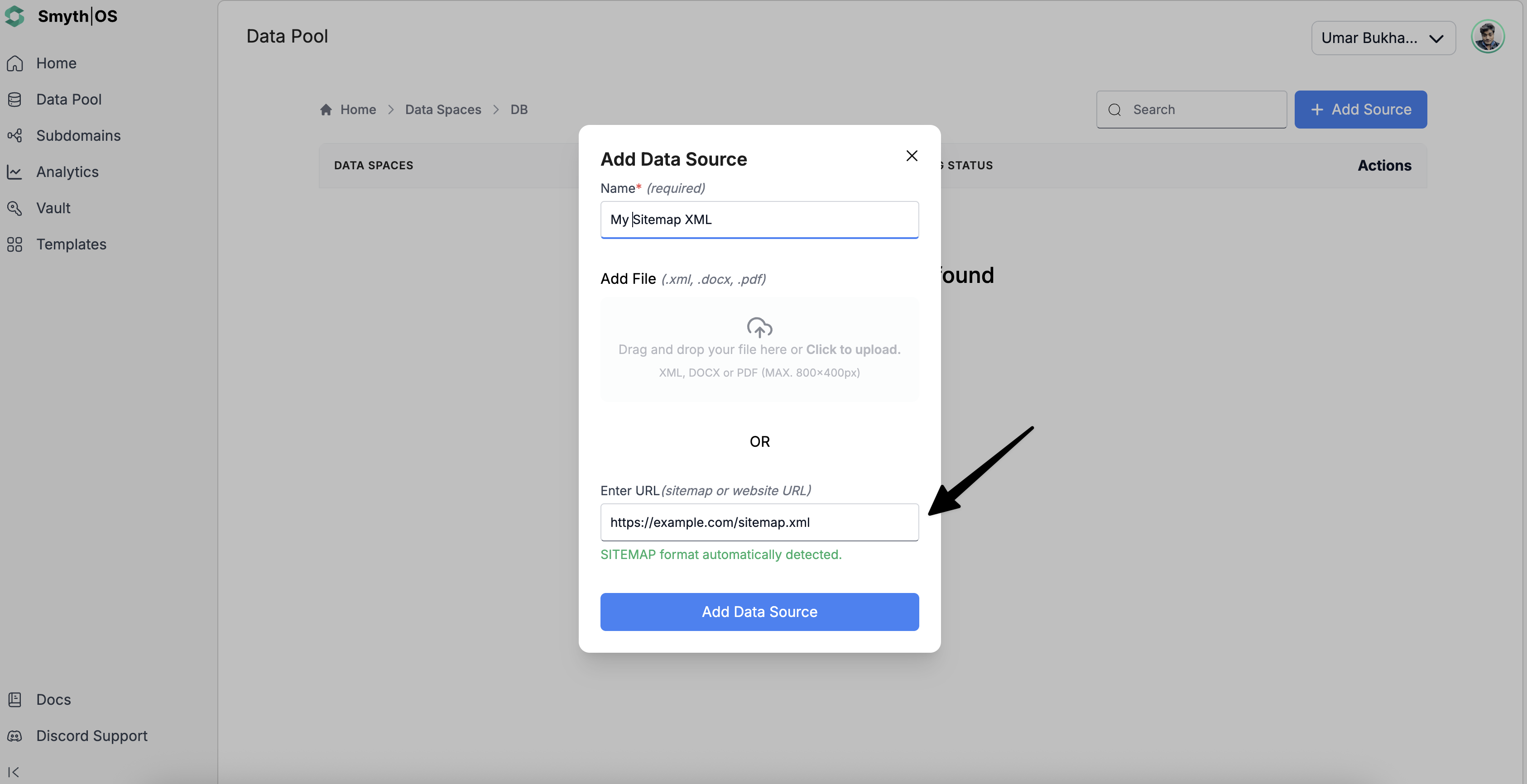
- Click *Add Data Source for it to start indexing.
SmythOS begins crawling and indexing immediately. You can monitor progress from the Data Pool dashboard.
Supported sitemap formats
SmythOS supports multiple types of sitemaps:
- Standard:
https://example.com/sitemap.xml,.xml.gz, or sitemap index files - News:
https://example.com/news-sitemap.xml - Images:
https://example.com/image-sitemap.xml - Videos:
https://example.com/video-sitemap.xml - Mobile:
https://example.com/mobile-sitemap.xml
Sitemap index files are fully supported. SmythOS will crawl each child sitemap listed within them.
Working with crawled data
Once indexing is complete, the content is available to agents via these components:
RAG Search
Use RAG Search to retrieve semantically relevant results from the sitemap content. Configure it to query the correct Data Space, adjust result count, and toggle metadata inclusion.
RAG Remember
Enhance a sitemap-based Data Space with additional content like manually written summaries or notes using RAG Remember. This is useful when you want to enhance the crawled data.
RAG Forget
Only manually added content can be removed using the RAG Forget component. Sitemap-crawled content is persistent and cannot be deleted through workflows.
Organising your Data Spaces
Single domain
Use one Data Space for each domain and add its sitemap. Best for simple websites or small teams.
Multi-domain
Use separate Data Spaces for each domain. Helps keep content clean and improves targeted search.
By content type
Segment by purpose (e.g., product pages vs. blog posts) using content-specific sitemaps.
Advanced: Custom Storage
For large sitemaps, enable Custom Storage using Pinecone. This lets you scale indexing, run advanced vector searches, and handle datasets with tens of thousands of pages.
| Feature | SmythOS Default | Custom Storage |
|---|---|---|
| Setup | No config needed | Pinecone required |
| Scalability | Medium | High |
| Advanced search | Basic | Vector ops |
| Manual tuning | Limited | Full API control |
Best practices
- Choose the main sitemap or index if available
- Avoid sitemap URLs that require login
- Split very large sitemaps into category-specific ones
- Confirm sitemap URL is valid XML and publicly accessible
Troubleshooting
| Issue | Steps to Resolve |
|---|---|
| Sitemap not processing | Verify URL is public and returns valid XML |
| Missing pages | Wait for full indexing or check Data Space selection |
| Poor query results | Add context via RAG Remember |
| Large sitemap slow | Use Custom Storage or split into smaller Data Spaces |
Using Sitemap Data in Agents
Agents can access crawled content through RAG workflows:
- Add the RAG Search component in a workflow
- Link it to the sitemap-enabled Data Space
- Use results in chat, APIs, or forms
For more, see how to connect Data Spaces to agents.
What's Next?
- Read more about Data Spaces
- Scale with Custom Storage
- Add crawled data to Spaces for agent use