
Late on 9 July 2025, xAI introduced Grok 4 through a livestream, calling it “the world’s most powerful model.” Alright, xAI! Let’s put that claim to the test.
The hour-long stream drew roughly 1.5 million concurrent viewers. It walked viewers through advanced math, black-hole visualizations, and lightning-fast voice replies.
But two points stood out immediately: It’s available now. And xAI is framing Grok 4 as postgraduate-level. Musk claimed the model “is smarter than almost all graduate students in all disciplines simultaneously.” Bold, sure, but those words are on record.
In this review, we’ll verify each claim by comparing benchmarks and abilities.
What is Grok 4 and How Does it Think?
At its heart, Grok 4 is a large‑language model much like GPT‑4o or Claude Opus. The twist, especially in the pricier Heavy tier, is the multi‑agent layer.
Picture 8, 16, or even 32 copies (according to Reddit users who inspected logs) of the model debating a problem, then merging their best answer.

During the livestream, Musk let Grok 4:
- Search the web in real time,
- Run short code snippets to crunch numbers, and
- Render simple visuals like orbital diagrams.
Why does that matter? Because benchmarks like Humanity’s Last Exam (HLE) spike when the model can fetch data or execute code mid‑thought. The Heavy tier leans on this tool use; the standard tier does far less of it.
Now, let’s talk latency. Voice replies feel conversational, roughly half the lag of Grok 2. According to post‑event press reports, xAI is targeting ~250 ms server‑side latency.
“Musk said the goal is to make responses ‘snappier,’ targeting roughly 250 ms round‑trip latency. “
As for the compute footprint, xAI stayed coy on exact GPU counts.
How Does Grok 4 Score? What Each Test Reveals
Below is the most complete scoreboard we have today. Each figure is either a direct quote from the livestream or a secondary claim flagged with its source. If a number isn’t on camera, we treat it as provisional.
| Task / Benchmark | Metric | Grok 4 (Standard) | Grok 4 (Heavy) | GPT-4o | Claude Opus 4 | Gemini 2.5 Pro | Source |
|---|---|---|---|---|---|---|---|
| Humanity’s Last Exam (HLE) | Accuracy | ~25 % | 41–50 % | 22 % | 18 % | 21 % | ✅ (livestream) for 25% benchmark |
| GPQA (Physics/Astronomy) | Accuracy | — | 87–88 % | 86.4 % | 84 % | 86.4 % | 🔄 (Community Tests) |
| AIME 2025 (Math) | % Correct | — | 95 % | 88.9 % | 75.5 % | 88.9 % | 🔄 (Community Tests) |
| SWE-Bench (Coding) | Task pass@1 | — | 72–75 % | 71.7 % | 72.5 % | 69 % | 🔄 (Community Tests) |
| ARC-AGI-v2 | Composite | — | 15.8 % | 8 % | 8 % | 7 % | 🔄 (Community Tests) |
Why “—” in some cells? xAI hasn’t published numbers for the standard model on those tasks, and no independent lab has filled the gap yet.
Third‑party results can shift as eval suites evolve. But the trend line is clear: the Heavy tier competes, sometimes edges out, today’s best-closed models, at least on academic tasks.
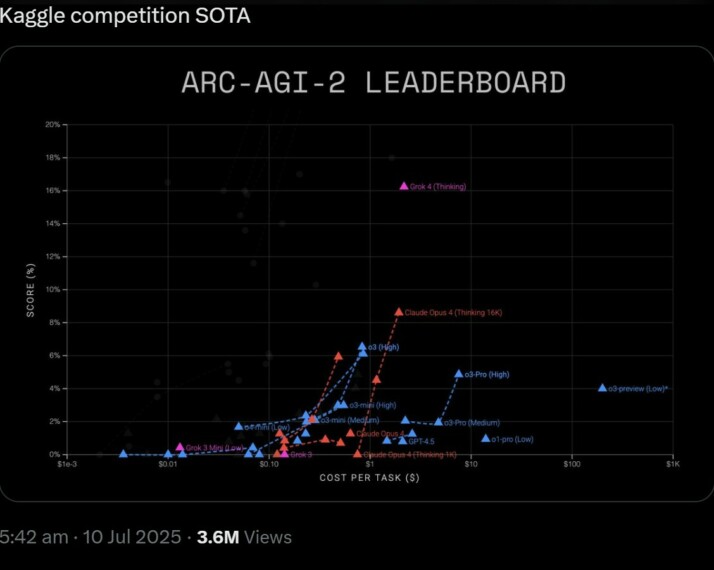
Price vs. Value: Does Heavy Earn Its Fee?
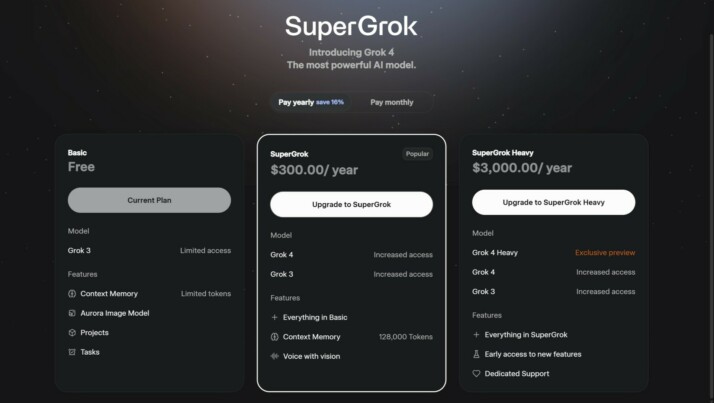
Two tiers, two very different service envelopes. At $30 a month, Grok 4 slots a little higher than GPT‑4o ($20) or Gemini ($20) but adds a lower target latency (~250 ms).
| Feature | Grok 4 Standard ($30) | Grok 4 Heavy ($300) | Note |
|---|---|---|---|
| Base model | Same 4-series weights | Same weights | No hidden performance tax on the cheaper tier. |
| Parallel agents | ❌ | Up to 32 agents (Reddit logs) | Main driver of higher reasoning scores. |
| Web search | ✅ | ✅ | Livestream showed both tiers fetching real-time facts. ✅ |
| Code execution | Short runtime (≈ 5 s, user tests) | Extended runtime (≈ 30 s, user tests) | Crucial for SWE-Bench; times are estimates. |
| Context window | 256 K tokens | 256 K tokens | Matches GPT-4o’s max. (press reports) |
| Rate limits | Tier-dependent (examples ≈ 20 qpm) | Tier-dependent (examples ≈ 120 qpm) | xAI hasn’t published fixed quotas; values may vary. |
| Voice latency | ≈ 500 ms (press estimate) | ≈ 350 ms (press estimate) | Both faster than Grok 3; exact figures unconfirmed. |
Why the Big Jump in Price?
xAI hasn’t disclosed exact GPU allocations, but Musk noted that Grok 4 Heavy spawns several parallel agents per request, which likely drives higher infrastructure costs. xAI hasn’t yet published details on rate-limit priority or queueing for Heavy subscribers.”
Who actually needs Heavy?
- Research labs running chain‑of‑thought experiments. Parallel agents mean fewer hallucinations when each agent checks the other.
- Code‑intensive startups that rely on test‑suite‑verified patches. Early internal tests show a 5–8 pp lift in patch accuracy.
- Voice assistants that must respond in < 400 ms; Heavy’s lower latency makes a real difference in spoken UX.
For everyone else, bloggers, hobbyists, and even many SaaS workflows, the standard tier is already competitive against GPT‑4o and Claude Opus. And xAI hinted during the stream that Heavy features may cascade down once infrastructure costs stabilise.
Open Questions: Data, Safety, and Transparency Gaps
We’ve covered what Grok 4 can do; here’s what xAI hasn’t spelled out yet:
Training Data Remains a Black Box
As of 10 July 2025, xAI has not released a data card or even a high‑level description of the corpora used to train Grok 4. External auditors can’t easily assess systemic bias or other risks without that transparency.
Hallucination is Still on the Radar
During the livestream, Musk admitted the model can sometimes “sound smart while being wrong.” That candid caveat is helpful, but it also signals that classic LLM pitfalls remain unresolved.
Multimodal Support is Promised, Not Delivered
Grok 4 can generate basic visuals, yet it can’t take images as input. Full multimodal interaction is slated for September, according to the livestream roadmap. But today you’re still chatting in text.
Final Verdict: Where Grok 4 Fits Today
In demos, Grok 4’s voice feels natural, and the web search plug‑ins save many steps of automating by hand.
If you’re a developer or startup founder, the $30 tier is a low‑risk way to gauge fit against GPT‑4o or Claude Opus. As a research lead or enterprise AI architect running high‑stakes reasoning pipelines, the $300 Heavy tier may earn its keep. But budget time for in‑house evals.
Either way, watch the changelog. xAI has a tight update cadence (coding‑specialist model in August, multimodal by September). Those milestones will decide whether Grok 4 becomes an everyday workhorse or stays a niche tool for early adopters.
Is it currently the world’s most powerful model? We’ll let you decide.