
Mistral AI released new speech understanding models on Tuesday. According to the company, “voice was humanity’s first interface,” and these models attempt to improve human-computer voice interaction.
Before now, automatic‑speech‑recognition (ASR) stacks were either open but error‑prone or accurate but locked behind pricey APIs.
Mistral AI’s two open‑weight models, Voxtral Small (24 B) and Voxtral Mini (3 B), ship under Apache 2.0 and hit state‑of‑the‑art accuracy. It also costs $0.001 per audio minute via API.
Has Mistral AI solved the dilemma in ASR? We’ll answer that question shortly.
What are Voxtral Models?
The Voxtral models are two open‑weight speech‑understanding models that share one architecture yet target different run-time realities.
Voxtral Small (24 B parameters) aims at multi‑GPU or cloud deployments where every fractional drop in word‑error rate moves the KPI needle.
On the flip side, Voxtral Mini (3 B parameters) runs in real-time on a single modern GPU or compact edge device. It’s ideal when data must stay on‑prem or when cloud latency is unacceptable.
However, the similarities between them are also noteworthy:
Open weights with flexible delivery
They are both distributed under the Apache 2.0 open-source license. You can either self‑host the checkpoints or call Mistral’s hosted API. The best part? A streamlined Transcribe endpoint is priced at $0.001 per audio minute. That’s less than half the cost of closed APIs like Whisper or ElevenLabs Scribe!
Multilingual proficiency
Also, they have automatic language detection with impressive scores across English, Spanish, French, Portuguese, Hindi, German, Dutch, and Italian.
32 k‑token context window
The models boast a 32k token context window, which is enough for 30 minutes of uninterrupted transcription. Or roughly 40 minutes when you provide comprehension and Q&A.
Built‑in reasoning
Seamlessly summarise, answer, or trigger backend functions directly from voice without piping the transcript into a second LLM.
Text‑level intelligence
Finally, they inherit the Mistral Small 3.1’s text-level intelligence. So, it can parse and reason over its transcripts in the same forward pass.
Benchmark Result: Does It Live Up to the Hype?
Mistral evaluated Voxtral on a suite of public benchmarks. The evaluation covered short‑form and long‑form English speech, eight Common Voice languages, nine FLEURS languages, an in‑house audio‑understanding set, and speech‑to‑English translation.
Scores are reported as macro‑average word‑error rate (WER) for transcription and BLEU for translation.
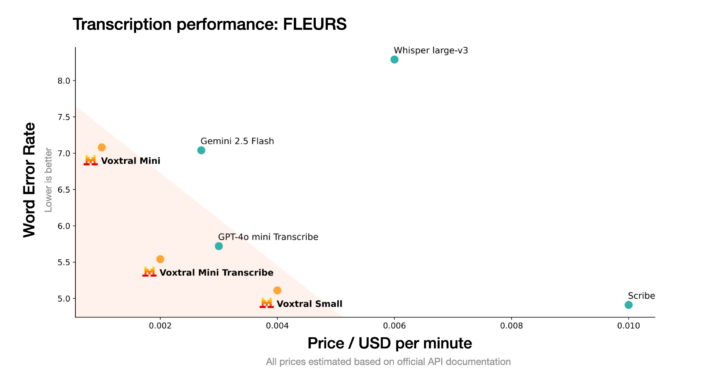
Across every transcription task, LibriSpeech, GigaSpeech, VoxPopuli, Switchboard, CHiME‑4, SPGISpeech for short clips, plus Earnings‑21/22 for ten‑minute audio, Voxtral Small records the lowest WER. The Voxtral Mini consistently comes second. Together, Both models beat Whisper large‑v3, the strongest open‑source baseline.
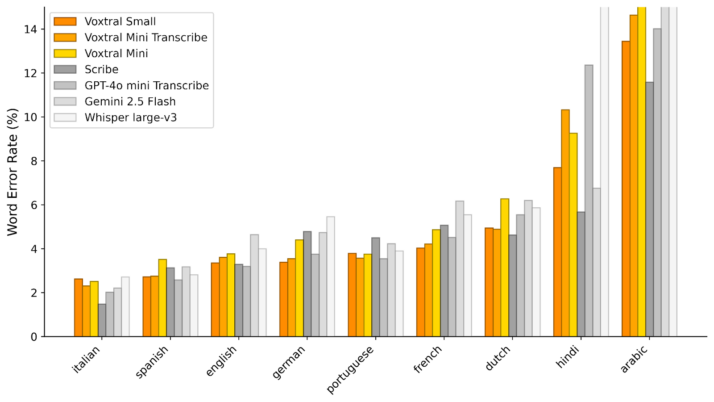
The multilingual story is the same. On Mozilla Common Voice 15.1 and the FLEURS corpus, Voxtral Small leads Whisper large‑v3 in all tested languages, including traditionally hard sets like Hindi and Arabic. Mini narrows but still maintains an edge over Whisper.
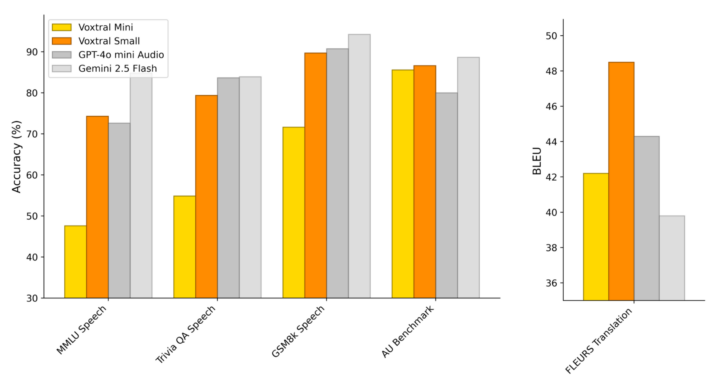
Beyond transcription, Mistral synthesised three standard text‑reasoning tasks into spoken form and added a 40‑clip Audio Understanding benchmark. Voxtral Small matches or outperforms GPT‑4o‑mini and Gemini Flash on these comprehension tasks. And it sets a new high BLEU score on FLEURS‑Translation.
Finally, MMLU and DROP confirm that audio pre‑training hasn’t dulled Voxtral’s text reasoning. Its curves overlap with Mistral Small 3.1.
What does this mean? The Small variant tops every open‑weight rival, while Mini overtakes Whisper, yet stays light enough for a single GPU.
Bottom Line
Apparently, Voxtral puts open‑weight, production‑grade speech intelligence on tap. The 32 k‑token context, built‑in reasoning, and API pricing that starts at $0.001 per minute position it ahead of its predecessors.
Speaking of the variants, the 24 B model tops every public benchmark while the 3 B model edges out Whisper large‑v3 and still fits on a single consumer GPU. You can reach out to Mistral for advanced enterprise features where necessary.
While there are more features in the pipeline, the models are ready for deployment today.