
The Phi family has been evolving at breakneck speed. On June 9, Microsoft released the latest addition to its family, the Phi-4 Mini Flash. As LLMs stretch into education, real-time tutoring, field devices, and personalized edge AI, speed and responsiveness have become essential.
This model caters to that need.
Phi-4-Mini Flash is built to think quickly, reason with precision, and do it all on lean infrastructure. According to Microsoft, it’s available on Hugging Face, Azure AI, and NVIDIA API Catalog.
What does this model have to offer? In this article, we’ll explore everything we know about Phi-4 Mini Flash from the benchmarks to the limitations.
What’s New?
Phi-4-Mini Flash is still a 3.8-billion parameter model, yes. But that’s just a number. What makes this version stand out is how it thinks.
Here’s what’s new:
SambaY Decoder: SambaY is a thoughtfully engineered hybrid that blends two very different mechanisms. Mamba (a state space model that’s great for memory and sequential information) and sliding window attention (which focuses on the most recent, relevant information).
The combination of these two mechanisms births a decoder that can reason across longer text while staying fast and light.
Gated Memory Units (GMUs): These smart, purpose-built tools are embedded in the cross-decoder. They allow the model to prefill sequences linearly, basically enabling it to scan ahead without breaking stride.
How is this a big deal? It comes in handy when you’re working with long prompts or data-heavy input. Instead of reloading every time it reads, the model coast smoothly through even dense material.
Cross-decoder Mechanism: Here’s where Microsoft engineers got creative. Instead of forcing the model to rely on full attention layers (which get computationally expensive very quickly), they only use one. Just one. That’s enough to establish the necessary connections without slowing everything down. The rest is handled by the more efficient Mamba and GMU components.
Together, this trio forms an architecture that’s… well, elegant. Lean and effective as opposed to being flashy or bloated.
It delivers up to 10× higher throughput and 2–3× lower latency than the original Phi-4-Mini. That means more interactions per second, less wait time, and a smoother experience—whether it’s embedded in a chatbot, a classroom tutor, or a warehouse scanner.
Benchmark Breakdown: What Does This Mean?
The benchmarks for a model this compact are striking. Here are the highlights:
Latency vs. Sequence Length
This is where Phi-4-Mini Flash shines. Most transformer-based models slow down dramatically as you feed them longer input. Phi-4-Mini Flash handles longer prompts with grace, thanks to its linear-prefill mechanism.
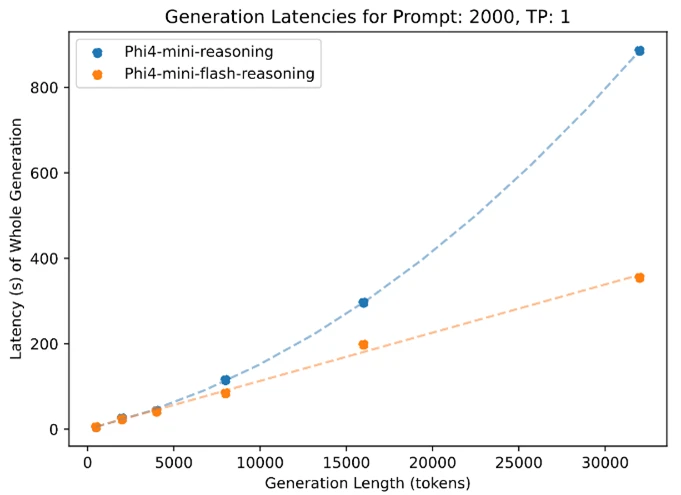
In actual testing with vLLM on a single A100-80 GB GPU, the latency grew far more gradually than with previous Phi versions or standard transformers.
Throughput Performance
In large-batch decoding scenarios, the model’s throughput scaled up to 10× compared to the original Phi-4-Mini. That’s a technical way of saying: more completions per second, more responsiveness, and fewer bottlenecks in deployment. Especially when serving multiple users concurrently.
Math & Logic Reasoning
Phi-4-Mini Flash achieved strong Pass@1 scores on tasks like GSM8K, AIME24/25, and Math500. In many of these, it either matched or exceeded the performance of 7–8B parameter models.
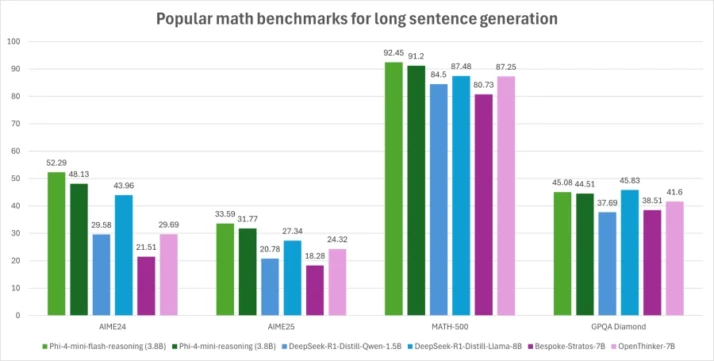
Notably, it performs well on reasoning-heavy benchmarks, which usually expose weaknesses in small models. This includes:
~73% on AIME24 (Math)
~69% on GPQA (Graduate-level QA)
~82% on DROP (Discrete reasoning over paragraphs)
Memory Efficiency
The model avoids quadratic attention scaling (thanks to its SambaY design). Hence, you don’t need expensive infrastructure to get great performance. It comfortably runs on a single modern GPU, and inference benchmarks confirm it can operate with lower VRAM ceilings than competitors.
Here’s the highlight in a clearer format:
| Benchmark Task | Phi‑4‑Mini Flash (3.8B) | Phi‑4‑Mini Reasoning (3.8B) | DeepSeek-R1-Distill (~7B) | Qwen-7B |
|---|---|---|---|---|
| AIME 24 | 52.29% | 48.13% | 55.5% | 53.70% |
| AIME 25 | 33.59% | 31.77% | — | 35.94% |
| Math 500 | 92.45% | 91.20% | 92.8% | 93.03% |
| GPQA Diamond (Grad QA) | 45.08% | 44.51% | 49.1% | 47.85% |
The Best Use Cases for Phi-4-Mini Flash
Phi-4-Mini Flash is purpose-built for efficiency, particularly in environments where latency and resource limits matter. That includes a wide range of practical applications.
Let’s break down where its strengths could be especially impactful:
Educational Tools
For classroom or remote learning scenarios, Phi-4-Mini Flash’s low-latency and fast inference make it suitable for integration into real-time tutoring systems and study aids. The sweet spot is when paired with lightweight devices.
Offline Intelligence
Its performance on a single A100 GPU hints at the potential for lower-end deployments. Although actual support on consumer-grade devices has not yet been demonstrated. Nonetheless, it presents an opportunity for more accessible offline AI processing in remote or infrastructure-limited settings.
On-Device Decision Support
In settings like logistics or mobile diagnostics, a fast, lightweight model can reduce reliance on cloud infrastructure. Phi-4-Mini Flash is suited for such deployment where decisions need to happen quickly and reliably.
While public, large-scale deployment examples haven’t been released yet, the architecture and efficiency of Phi-4-Mini Flash point to a strong fit for embedded reasoning tasks.
Final Thoughts: What Phi-4-Mini Flash Actually Delivers
Phi-4-Mini Flash Reasoning proves that thoughtful architecture can outpace size. It offers just enough power where needed for developers who care about responsiveness, or teams building edge-first experiences. Compact. Fast. Measured. Reliable. That’s what this model brings to the table. If AI is going to be everywhere, it should work anywhere. And now, it can.