
Finally, the long awaited OpenAI’s GPT-5 is here.
It launched Thursday, August 7th 2025 and it’s the first foundation model to actively decide how smart it needs to be while it’s responding to you.
Altman stated that he believes the new model is so smart that opting for its predecessor GPT-4, feels “quite miserable” in comparison.
Now, that’s all hype—until it’s not. Beyond the claims, this article pulls back the curtains on what GPT 5 truly has to offer. Let’s see what the hype is about.
A Smarter System: The Router Model at the Core
The most consequential upgrade in GPT-5 isn’t bigger weights or longer context. It’s how the model thinks about thinking.
GPT-5 doesn’t rely on a single monolithic network like its predecessors. Instead, it’s a three-part system:
A fast “smart” model for routine, low-latency prompts
A deeper “thinking” model for complex reasoning or nuanced tasks
A router that learns, based on user behavior, prompt complexity, and feedback, which model to activate for each request
Interestingly, this router improves in production, using live signals such as: thumbs up/down on completions, user edits and retry patterns, whether follow-up prompts lead to rerouting or better outcomes.
This setup gives GPT-5 the flexibility to balance cost and performance in real time. When you don’t need heavyweight reasoning, it doesn’t waste GPU cycles. But when stakes are higher for instance, debugging multistep code, it dials up the reasoning power.
This unlocks a new class of architecture: dynamic intelligence scaling, based on context, not just prompt tuning.
So, What’s New?
The new model ushers in a more helpful and overall smarter version of previous GPT models. Here’s what actually changed with GPT-5:
Instruction Following with Fewer hallucinations.
On the MultiChallenge benchmark, GPT-5 scores 69.6%, outperforming GPT-4o by nearly 9 points. More importantly, it cuts factual errors by ~80% on LongFact, one of the few tests designed to probe real-world hallucination risks.
That makes it safer in logs, UI text, and automated reports or places where made-up facts cause real damage.
Agentic Tool Use
On the telecom-heavy Tau2-bench (telecom), GPT-5 scored 96.7%. This is a clear leap in how well it handles structured tool calls. For developers building multi-hop agents, this is huge. It means fewer broken chains, and more autonomy in longer workflows.
True long-context reasoning
GPT-5 supports up to 272k tokens of input and 128k output in a single call. That’s enough to handle entire codebases, or multi-user chat logs, without chunking or retrieval workarounds. And it doesn’t just store that span, it can reason across it, provided the input is well-structured.
Developers can control GPT‑5’s thinking time via the reasoning_effort parameter in the API. In addition to the prior values—low, medium (default), and high—GPT‑5 also supports minimal, which minimizes GPT‑5’s reasoning to return an answer quickly.
– OpenAI
Three Sizes
GPT-5 is available in three variants: gpt-5, gpt-5-mini, and gpt-5-nano. The flagship model is priced at $1.25 per million input tokens and $10 per million output tokens.
While exact pricing for the smaller variants hasn’t been published yet, OpenAI notes they are optimized for lower-cost deployments. Hence, they are well-suited for latency-sensitive or budget-constrained use cases.
Safety Training
Open AI introduced a new form of safety training, safety completions. This ensures GPT-5 gives helpful answers with safe boundaries. It’s a quieter, more honest model that knows when to step back and is willing to admit when it can’t help.
Capability Snapshot: Where GPT-5 Pushes the Envelope
GPT-5 is a step-change in reasoning, code editing, and multimodal understanding compared to its predecessors. And this fact is backed by real, public benchmarks. Here’s a breakdown of how GPT-5 performs where it counts:
| Domain | Benchmark | GPT-5 | GPT-5 Mini | GPT-5 Nano | GPT-4o | Key Takeaway |
|---|---|---|---|---|---|---|
| Math (No Tools) | AIME ’25 | 94.6% | 91.1% | 85.2% | 86.4% | Olympiad-grade logic & algebra |
| Open-domain QA | GPQA Diamond | 85.7% | 82.3% | 71.2% | 83.3% | Graduate-level STEM answers |
| Multimodal Reasoning | MMMU | 84.2% | 81.6% | 75.6% | 82.9% | Visual + logical understanding |
| Coding (Real-world) | SWE-bench Verified | 74.9% | 71.0% | 54.7% | 69.1% | PR-grade GitHub fixes |
| Code Editing | Aider Polyglot | 88.0% | 71.6% | 48.4% | 79.6% | Diff-aware, multi-language edits |
| Instruction Following | Scale MultiChallenge | 69.6% | 62.3% | 54.9% | 60.4% | Fewer failures in complex tasks |
| Tool Use (Agents) | Tau2 Telecom | 96.7% | 74.1% | 35.5% | 58.2% | Handles long tool chains well |
| Long-context Reasoning | OpenAI-MRCR (128k) | 95.2% | 84.3% | 43.2% | 55.0% | Tracks info across large docs |
| Hallucination Rate | LongFact Concepts | 1.0% | 0.7% | 1.0% | 5.2% | Much more grounded answers |
GPT-5 in Action: Fine-Grained Multimodal Demos
When it comes to front-end code for web apps, GPT-5 builds with more purpose. It’s more aesthetically aware, more structurally ambitious, and noticeably more accurate than its predecessors.
In side-by-side comparisons with GPT-4o, GPT-5’s UI code was preferred by human testers 70% of the time. The reason? Here’s why:
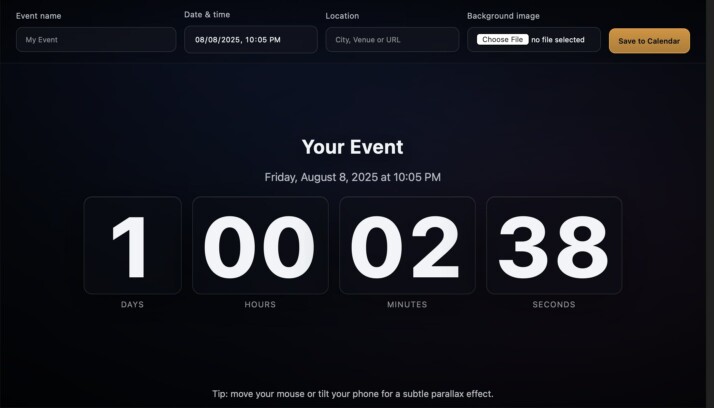
Prompt: Create a single-page app in a single HTML file that builds a live event countdown. – Inputs: event name, date/time, location, background image upload. – Display large animated countdown numbers, subtle background parallax effect, and a “Save to Calendar” button.
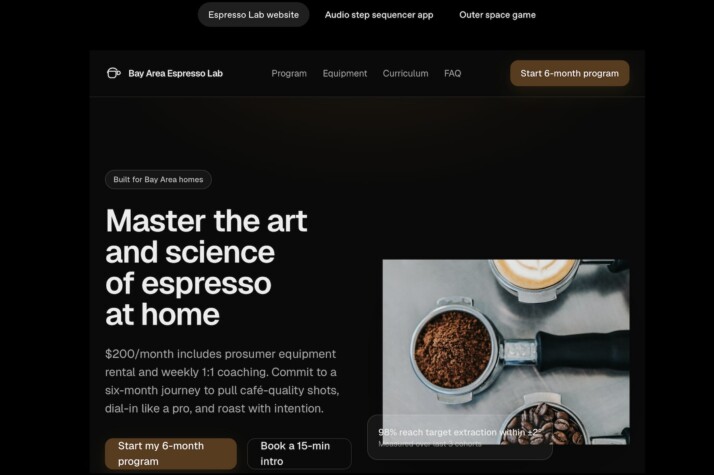
Prompt: Please generate a beautiful, realistic landing page for a service that provides the ultimate coffee enthusiast a $200/month subscription that provides equipment rental and coaching for coffee roasting and creating the ultimate espresso. The target audience is a bay area middle-aged person who might work in tech and is educated, has disposable income, and is passionate about the art and science of coffee. Optimize for conversion for a 6 month signup.
See more here.
What OpenAI Admits: Trade-Offs You Should Know
In both its launch post and the press release, the OpenAI team openly acknowledged architectural trade-offs in GPT-5.
When the router selects the deeper “thinking” model, it unlocks more sophisticated reasoning but at a cost: higher inference compute and longer first-token latency.
For teams building customer-facing UX, real-time chat, or fast-response agents, this shapes how and when GPT-5 can be used effectively.
How GPT-5 Stacks Up Against Other Models
Let’s take a look at real numbers:
| Model | SWE-bench Verified | AIME 2025 | Context Limit | Notable Edge |
|---|---|---|---|---|
| GPT-5 | 74.9% | 94.6% | 400k tokens | Router + test-time compute |
| Gemini 2.5 Pro | 68% | 90% | 1M tokens | Native multimodal + long docs |
| Grok 4 | 59% | 85% | 128k tokens | Real-time X (formerly Twitter) |
| Mistral 405B | 61% | 82% | 256k tokens | Open weights, local deployment |
Key takeaways:
GPT-5 leads in precision reasoning and code correctness. It performs better on pull-request tasks and advanced math than any known public model.
Gemini 2.5 Pro still dominates in multimodal scale and retrieval-heavy tasks. With a 1M context window, it’s more suitable for extremely long documents.
Grok 4 brings the edge on real-time web data, especially in current events or pop culture queries, due to its integration with X (formerly Twitter).
Mistral 405B is for teams that need transparency and control—its weights are open, and it runs well locally on high-end GPUs.
If you’re building a system that demands deep reasoning, flexible latency, and fewer hallucinations, GPT-5 is now the benchmark to beat.
Start Building with GPT-5 on SmythOS
Time to take GPT-5 for a spin. GPT‑5 is now embedded into SmythOS so you can call state-of-the-art reasoning and code generation from your favorite interface without spinning up external APIs or worrying about latency.
Below you’ll see a few rich screenshots that show how simple it is to get started:
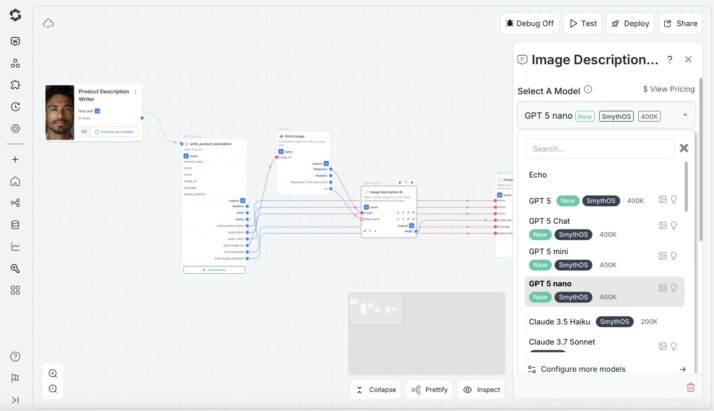
A quick glance at the LLM Component Settings —just choose GPT‑5 or GPT‑5 Chat, GPT-5 mini, or GPT-5 Nano and let SmythOS handle the rest.
Here’s what a result generated using GPT-5 looks like:
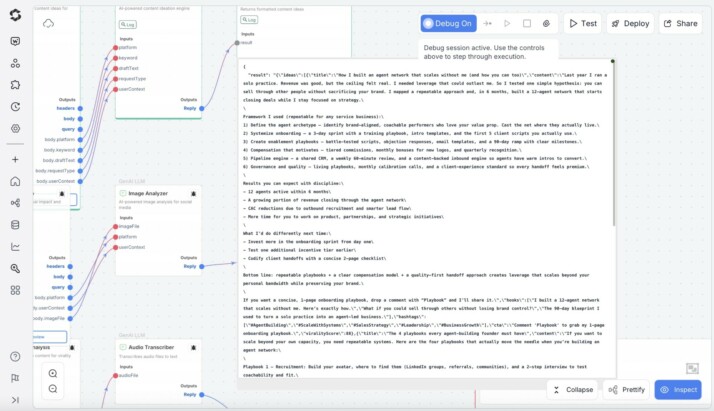
Whether you’re in the middle of debugging, building tools for your team, or prototyping clever features, GPT‑5 on SmythOS feels like an ally. Go ahead, access all the features GPT-5 has to offer on SmythOS!
Availability and Access
GPT‑5 is now the default model in ChatGPT, replacing GPT‑4o, GPT‑4.1, and earlier variants for signed-in users.
To use it, simply open ChatGPT and it’s available. For more control, Pro users can select GPT‑5 Thinking from the model picker or guide behavior using instructions.
Availability:
- GPT‑5 is rolling out to Plus, Pro, Team, and Free users starting today.
- Enterprise and Edu users will receive access within a week.
- Pro, plus and team users can now code with GPT 5 through the Codex CLI.
Overall, A Smarter Model
GPT-5 introduces a new class of features built for real-world development. For developers, this model means: more control over performance, latency, and verbosity. Fewer edge-case failures in long-form logic and multi-tool workflows. And for the first time, the ability to scale “how smart” the model is dynamically, per task.
Beyond being a smarter model, GPT-5 is a smarter system. And in 2025, that distinction matters.
If you’re building AI into products, infrastructure, or research, GPT-5 is a release worth considering. Not because OpenAI says so. But because the model seems to show its work.