
Gemini just proved that AI in robotics doesn’t have to be cloud-bound with little latency. It just introduced the new Robotics on-device. According to Google, it’s their “most powerful VLA model optimized to run locally on robotic devices.”
Google’s newest AI system for robots is a major shift in how and where intelligence lives in machines.
How is Gemini Robotics On-Device Different?
Back in March, Google introduced Gemini Robotics, a large Vision-Language-Action (VLA) model that extended Gemini 2.0’s reasoning into the physical world.
That model lived in the cloud. Now, its on-device sibling takes those same capabilities and packages them for local deployment, specifically for bi-arm robots.
This means robots can see, understand, and act using multimodal reasoning—vision, language, and physical interaction. All these without ever connecting to the internet. It’s built to operate completely offline.
Key Capabilities: What Gemini Robotics On-Device Can Actually Do
A lot. Here’s a look at the capabilities that matter:
Follow Natural Language Instructions
Gemini Robotics On-Device understands open-ended language inputs and converts them into precise robot actions. According to Google, it parses instructions just like its cloud counterpart and executes locally.
Manipulate Unfamiliar Objects
It can generalize to new objects and scenes, thanks to the embodied reasoning and spatial understanding. Gemini Robotics On-Device handles tasks like grasping, pouring, or picking out specific items by interpreting affordances and spatial cues. All without prior exposure to any of the tasks.
Complete Complex and Multi-step tasks
Tasks like folding clothes, packing lunchboxes, or even wrapping headphone wires are multi-step actions that require coordination, memory of intermediate states, and dynamic planning. The new Gemini Robotics executes these kind of tasks in real time.
Adapt to New Tasks with Just 50–100 Demonstrations
The model adapts to brand-new tasks with minimal fine-tuning using in-context learning. In benchmark tests, it learned to draw cards, zip containers, pour dressings, and perform several tasks of varied complexity with just a few examples. This kind of sample efficiency is remarkable in traditional robotics.
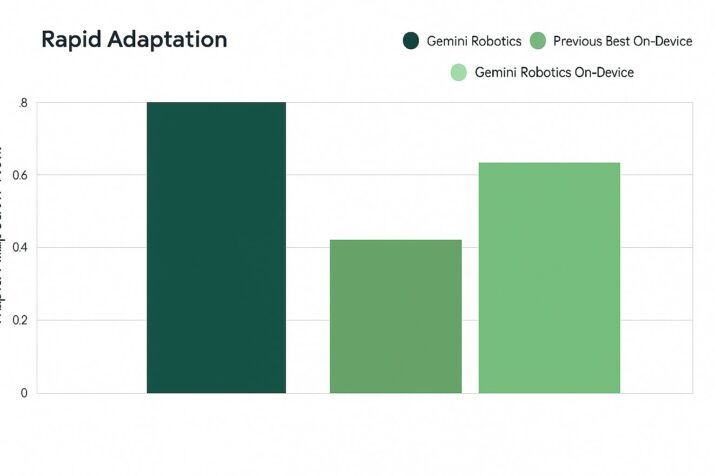
Generalization Performance That Stands Out
According to Google’s technical evaluations:
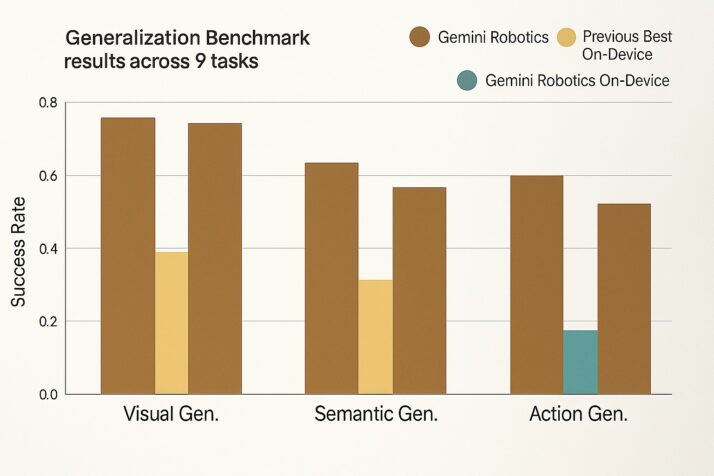
- The new model outperforms prior on-device models across a wide suite of out-of-distribution (OOD) tasks. This includes novel object configurations and multi-step language instructions.
- Gemini Robotics On-Device maintains robust accuracy under distribution shift.
- It also achieves instruction-following accuracy that closely rivals the flagship cloud-based Gemini Robotics, while running entirely on-device.
- Finally, it showed strong performance even with fewer than 100 fine-tuning examples across seven dexterous manipulation tasks.
Simply put, it adapts quickly, transfers broadly, and handles real-world variability like no other on-device system in its class. Most robots need specialized models for every little variation. Gemini Robotics On-Device doesn’t.
According to Google’s benchmarks, Gemini Robotics On-Device outperforms the best on-device models to date. In fact, it even holds up surprisingly well against its cloud-powered sibling when running locally, especially in generalization and instruction-following tasks.
Why On-Device Model Matters
Let’s get real for a second. In the lab, cloud-based robotics is fine. In a factory or a field hospital with spotty Wi-Fi? Not so much.
On-device models solve that. You get:
- Low latency
- No dependency on constant network access
- Higher resilience in high-stakes environments
Local inference reduces the risk surface for privacy-sensitive tasks. If your robot is assembling medical devices, the last thing you want is to stream camera data off-site.
Built for Bi-Arms
The model was originally trained on Google’s ALOHA robot, which has two arms. But that doesn’t mean it’s locked in. Developers have already adapted it to:
Franka FR3 (another dual-arm platform) for tasks like dress folding and belt assembly
Apptronik Apollo (a humanoid robot) for general manipulation
That kind of transferability is rare. It suggests a generalist foundation model, one capable of cross-embodiment reasoning. The best way to describe it is the same brain jumping between different robot bodies.
Developer Toolkit: SDK Access and Fine-Tuning Tools
Along with the model, they’re releasing the Gemini Robotics SDK.
With it, developers can:
- Test in MuJoCo physics simulator
- Evaluate model behavior in custom environments
- Fine-tune the system with as few as 50 samples
Access is currently limited to their trusted tester program. Which, to be honest, is wise. Any system this powerful deserves careful rollout.
Responsible AI in Physical Systems
Google’s taking safety seriously at both the software and hardware levels. The model interfaces with low-level controllers for physical execution and uses semantic safety filters for content. There’s a dedicated ReDI team overseeing development impact and a Responsibility & Safety Council reviewing system risk.
Also, they recommend red-teaming every layer of the stack. That’s a cue for developers: don’t skip your threat models.
Real-World Impact: Practical Uses and Industry Applications
This launch is a huge milestone for Google. It’s a blueprint for how AI could be embedded in real-world robotics.
It opens doors for local robotics applications in healthcare, manufacturing, logistics, defense, and domestic environments. Especially in places where low latency, data privacy, and network independence are non-negotiable.
We’re seeing a move away from “just connect to the cloud” toward “think where you stand.”
That changes everything.
Conclusion: A Practical Leap for Embodied AI
Gemini Robotics On-Device is efficient, quiet, and surprisingly capable. And in the world of robotics, that’s the real flex.
It won’t solve robotics overnight. But it’s a sharp step forward, bringing brains to the edge, where machines actually live.