
Anthropic’s release of Claude Opus 4.1 on August 5 was yet another targeted, practical improvement.
This new model is a refined form of its predecessor, Opus 4. Opus 4.1 is engineered to be a more capable tool for complex, real-world coding, in-depth reasoning, and building more reliable AI agents. For developers, this translates to a model that aims for precision where it matters most.
Is that really the case with Claude Opus 4.1?
This review covers all the basics from its capabilities to tradeoffs and benchmarks.
Where Opus 4.1 Stands Out
Anthropic zeroed-in on three fronts where nuance matters:
Precise Coding Assistant
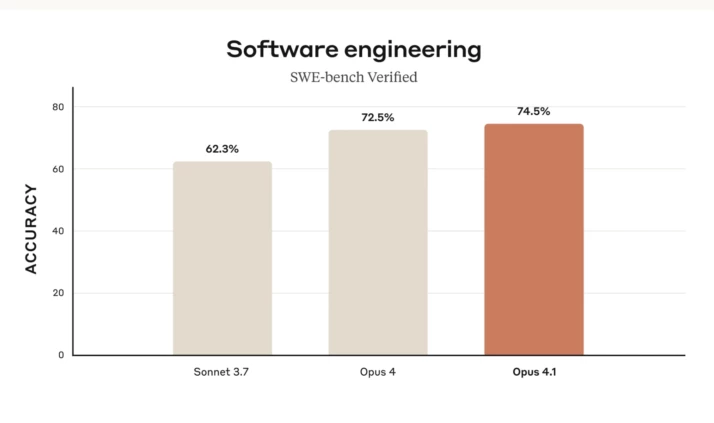
Opus 4.1 posts a new state-of-the-art 74.5 % on SWE-bench Verified, a benchmark that checks whether a model can land real GitHub pull requests without breaking nearby code. This score suggests a notable improvement in practical coding ability over its predecessor and competitors.
Early testers like GitHub and the Japanese e-commerce giant Rakuten have reported that Opus 4.1 excels at navigating multi-file codebases.
Instead of making broad, often clumsy edits, the model demonstrates a more surgical precision. Even better, it identifies the exact lines that need correction across different files and implements changes without introducing new bugs.
More Autonomous and Capable Agents
Opus 4.1 tightens its grip on multi-step workflows. On the Tool-Augmented-Reasoning benchmark (TAU-bench) it edges up on the retail track (82.4). So, it’s more adept at handling complex, multi-step workflows that require maintaining context and a clear goal over an extended period.
As a developer, this translates to building agents that are less likely to get sidetracked or “forget” their primary objective during a complex operation. Seems like a great choice for conducting market research and using the findings to draft a business plan.
Deeper Reasoning
Perhaps the most novel feature in Opus 4.1 is its hybrid reasoning system. By default, the model delivers rapid answers, but you can enable Extended Thinking by adding a thinking block to your API call. You then set thinking budget tokens which could be any value from 1,024 up to just under the model’s 32 000-token max tokens cap.
How Opus 4.1 Performs and What It Will Cost You
Day-to-day workloads reveal what Opus 4.1 really delivers and what it costs:
Performance in the Real World
| Benchmark / Task | Claude Opus 4.1 | Claude Opus 4 | Claude Sonnet 4 | OpenAI o3 | Gemini 2.5 Pro |
|---|---|---|---|---|---|
| Agentic coding SWE-bench Verified1 | 74.5 % | 72.5 % | 72.7 % | 69.1 % | 67.2 % |
| Agentic terminal coding Terminal-Bench2 | 43.3 % | 39.2 % | 35.5 % | 30.2 % | 25.3 % |
| Graduate-level reasoning GPQA Diamond | 80.9 % | 79.6 % | 75.4 % | 83.3 % | 86.4 % |
| Agentic tool use TAU-bench | Retail 82.4 % | Retail 81.4 % | Retail 80.5 % | Retail 70.4 % | — |
| Airline 56.0 % | Airline 59.6 % | Airline 60.0 % | Airline 52.0 % | — | |
| Multilingual Q&A MMMLU3 | 89.5 % | 88.8 % | 86.5 % | 88.8 % | — |
| Visual reasoning MMMU (validation) | 77.1 % | 76.5 % | 74.4 % | 82.9 % | 82 % |
| High-school math competition AIME 20254 | 78.0 % | 75.5 % | 70.5 % | 88.9 % | 88 % |
Footnotes (1 – 4) can link to your methodology or citation section as needed.
On paper, the benchmarks place Opus 4.1 at the forefront for certain coding tasks, particularly its lead over models like GPT-4o on SWE-bench. However, the developer experience is more textured than a single number.
Qualitative feedback from early users offers a clearer picture. The consensus is that Opus 4.1 generates code that feels more “thoughtful” and complete.
It often produces robust, production-ready solutions on the first try, reducing the need for iterative prompting and debugging. Frankly, a competitor might generate a faster, more direct answer. But Opus 4.1’s output is frequently described as resembling that of a seasoned developer who considers edge cases and code structure from the outset.
What are the Tradeoffs?
First is the cost. At $15 per million input tokens and $75 per million output tokens, Opus 4.1 is a premium tool. A single complex coding request can run several dollars.
Needless to say, it’s unsuitable for high-volume, low-cost applications. Anthropic does offer cost-mitigation features like batch processing for a 50% discount and prompt caching. But the base price positions it firmly as an investment.
Secondly, the speed-for-quality exchange. The model’s deliberative nature can make it slower than its competitors for simple, straightforward requests. However, its value emerges when the complexity of the task justifies a slightly longer wait for a higher-quality result.
Finally, there’s the nature of its intelligence. Some users have noted that the model can be “too clever,” occasionally over-engineering a simple solution. For tasks that require strict adherence to a basic pattern, this tendency to think deeply can be a hindrance. Overall, as with any other powerful tool, it requires careful application.
Getting Your Hands on Opus 4.1
Accessing Opus 4.1 is straightforward. It is available immediately for all paid Claude Pro and Team plan subscribers through the web interface and the dedicated Claude Code environment.
For developers looking to build with it, you can call the model via the Anthropic API using the model ID: claude-opus-4-1-20250805. It has also been rolled out to major cloud platforms, including Amazon Bedrock and Google Cloud’s Vertex AI, allowing for integration within existing cloud-native workflows.
Conclusion: Is Opus 4.1 Worth Trying?
The answer depends entirely on your needs. Opus 4.1 isn’t a one-size-fits-all replacement for other models but a specialized instrument honed for precision and depth.
The improvements in coding accuracy, agentic reliability, and deep reasoning provide tangible value for those tackling complex engineering and research challenges.
In essence, for the right tasks, Opus 4.1 could be a silver bullet.