The world is already saturated with information. The true challenge today is efficient retrieval. Finding the right answer is difficult when it’s hidden across countless files. This is a problem every developer and organization knows well.
To tackle this, SmythOS has partnered with a faith-based organization facing this exact challenge. Their members and staff needed to access information from many different sources. These included complex theological texts and internal operational documents. The goal was to eliminate the need for technical skills or hours of manual searching.
Our solution was a SmythOS AI agent. It ingests their vast knowledge base to provide instant, structured answers. In this post, we down how we built it. We will explore the technical architecture, performance results, and key learnings.
From Information Overload to Instant Clarity
The core problem was straightforward: users needed answers, but the knowledge was locked away in unstructured formats.
A simple keyword search was inefficient, often returning entire documents instead of specific answers. This created a frustrating experience for users, who had to manually sift through dense texts. For the members of this organization, this system created a bottleneck, limited engagement, and led to inconsistent information sharing.
Our goal at SmythOS was to create a system that could act as an expert, capable of understanding natural language questions and retrieving information with human-like precision.
Our Solution: An Intelligent Knowledge Agent
We developed an AI agent that serves as a single, intelligent interface to the organization’s entire knowledge base. Instead of just a search tool, it functions as a knowledgeable partner in the user’s quest for information.
A Unified Gateway to All Knowledge
The first step was to break down data silos. The agent was designed for universal data intake, allowing it to accept content in any format—documents, raw text, or URLs.
This material is then processed into a unified data pool, creating a centralized, searchable source of truth. This means that from the user’s perspective, all information, regardless of its original format, lives in one accessible place.
From Query to Answer: An Intelligent Workflow
Once the knowledge is centralized, the agent’s intelligence comes into play. When a user asks a question, a process of smart question handling begins. The agent first classifies the intent behind the query to understand what the user is truly asking for.
Following this, it employs a Retrieval-Augmented Generation (RAG) methodology to fetch the most relevant information segments from the data pool. Finally, these retrieved snippets are passed to LLM-powered components, which synthesize them into a clear, natural-sounding, and accurate answer.
Ensuring Transparency and Trust
To ensure reliability and facilitate continuous improvement, we implemented seamless logging.
Every question and its corresponding answer are automatically recorded into a Google Sheet. This simple but powerful feature provides complete transparency, creating an invaluable resource for debugging, analysis, and maintaining a clear audit trail.
Technical Deep Dive: Under the Hood
For developers, the magic is in the implementation. Let’s explore the architecture and the technical choices that powered this agent.
The Foundational Framework and Architecture
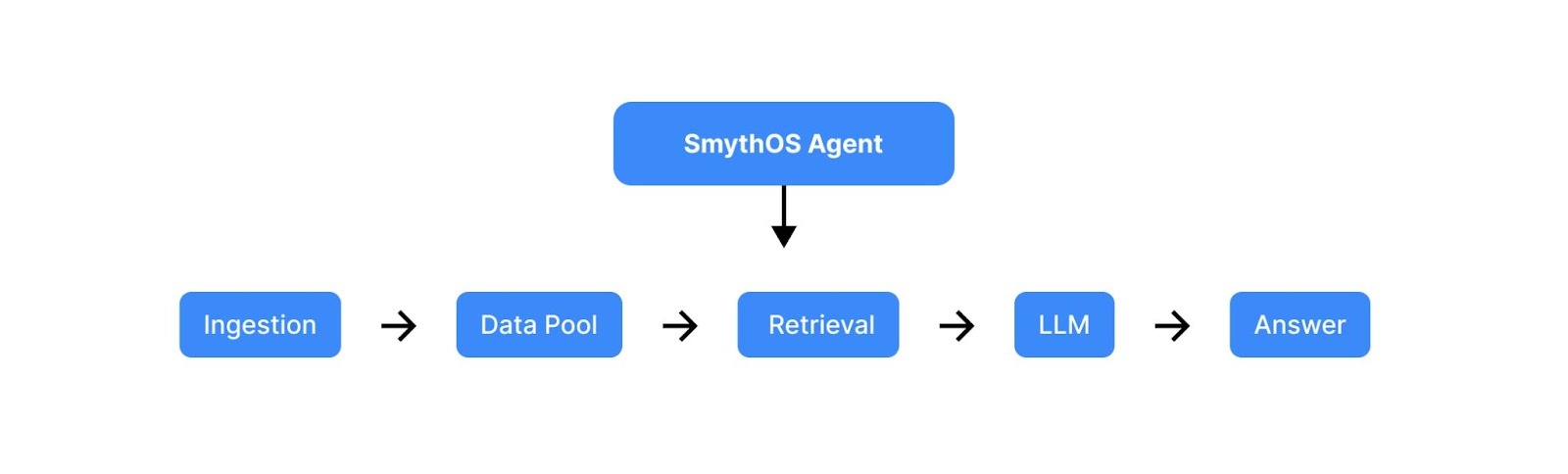
The entire system was built on the SmythOS AI Agents framework. The organization chose SmythOS for two main reasons: its powerful, out-of-the-box RAG system and its remarkably smooth, low-code building process, which significantly accelerated development.
A key requirement was modularity. The architecture allows developers to swap out core components, such as using a different LLM or vector store, without needing to re-architect the entire workflow.
The journey of a query from user to answer follows a lean and effective pipeline. It begins with ingestion, where content is fed into the data pool. When a user submits a query, the system moves to retrieval, where the RAG system finds relevant context. This context is then passed to an LLM for paraphrasing and generation, and the final output is delivered to the user while the interaction is logged.
Data Ingestion and Processing
The agent is able to seamlessly handle the various file formats like PDFs, DOCX, and HTML, because the SmythOS framework automatically parses them upon ingestion.
Our initial implementation required minimal preprocessing, as data is added directly to the pool. This is possible because the SmythOS RAG system is highly precise at retrieval even from raw content, which simplifies the pipeline and reduces overhead. Even for very large documents, the framework’s retrieval implementation maintains high precision.
The Core of Retrieval and Classification
At the heart of out agent’s intelligence is the RAG pipeline. . This process hinges on converting text to meaning, which is where OpenAI embeddings come into play.
These embeddings, which are numerical representations of the text, are stored and indexed in a vector database managed within SmythOS.
When a user asks a question, an LLM-based intent classifier first determines the query type. This crucial step helps tailor the retrieval strategy for optimal results. To ensure accuracy, retrieved results are then ranked by cosine similarity against the query embedding, and this score is further refined with metadata weighting. Only the top-ranked results are passed to the LLM for the final answer generation, ensuring the model works with the most relevant context.
Deployment, Scaling, and Optimization
To prepare for production use, the system runs in containers managed by SmythOS, which simplifies both deployment and scaling. Thanks to its stateless design, the agent can handle concurrent queries from many users simultaneously without performance degradation.
To keep responses real-time under load, we implemented several optimizations, including caching frequently accessed data and leveraging asynchronous I/O operations to prevent blocking.
The Impact: A Transformation in Numbers
The deployment of the AI agent yielded significant, measurable improvements across the board. The results speak for themselves.
A Leap in Accuracy and Reliability
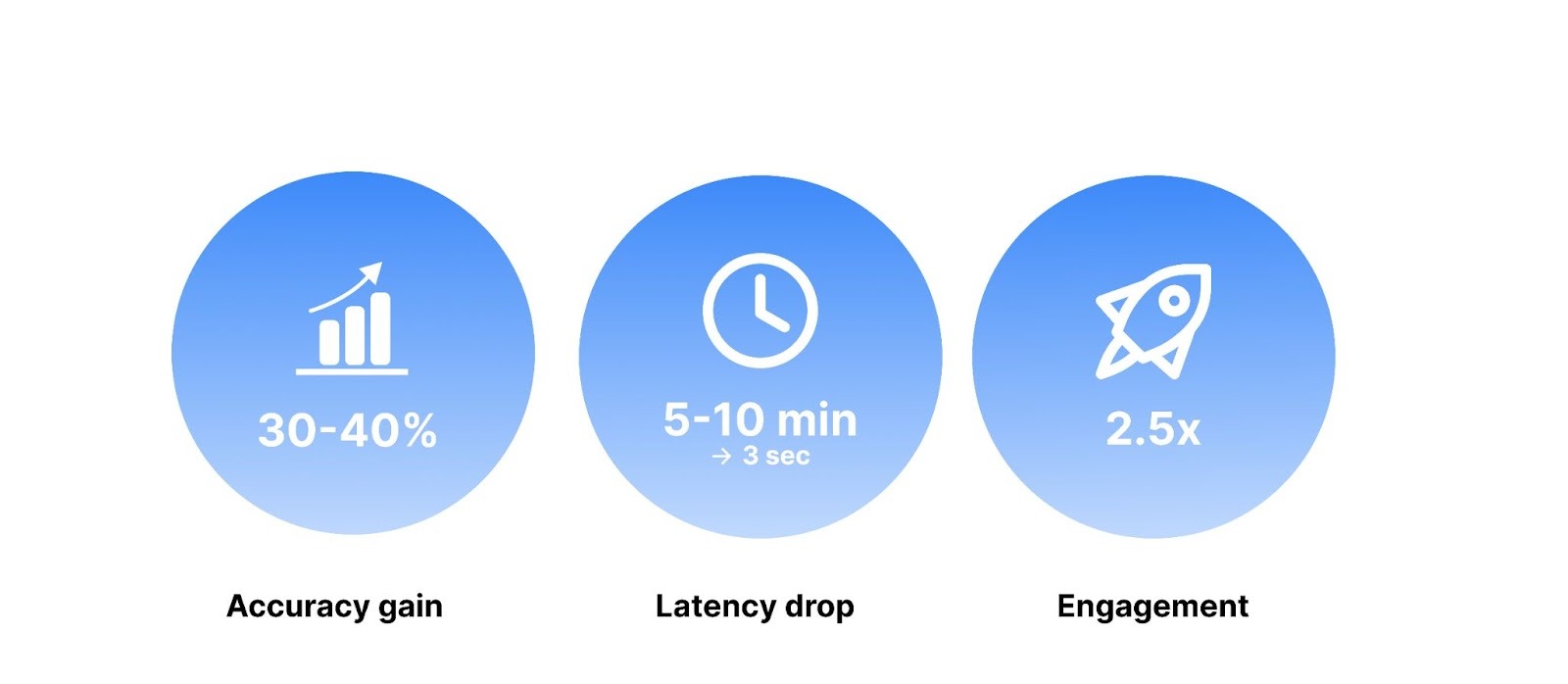
We immediately observed a 30–40% improvement in answer accuracy compared to the previous manual search methods. Furthermore, the system demonstrated high relevance, with fewer than 10% of queries returning irrelevant results. This is actively mitigated by a reranking layer that refines search results before the generation step, ensuring users receive correct and useful information.
Transforming Speed and Performance
Perhaps the most dramatic change was in user efficiency. Average search time plummeted from 5–10 minutes to under 3 seconds. This radical reduction in latency was the result of targeted optimizations.
While latency increases linearly with the size of the data pool, we identified embedding retrieval as the primary bottleneck and optimized it with advanced caching and pruning techniques.
Boosting User Engagement and Adoption
When users can trust a system to be both fast and correct, they naturally use it more. Following the deployment, user engagement increased by 2.5x. We saw a rise in both the volume of queries and the number of repeat users.
The agent successfully tackled even multi-hop queries—those requiring multiple pieces of information—by refining our chunking and retrieval logic to better capture interconnected concepts.
Achieving Scalability and Cost-Efficiency
The system was built to scale, reliably supporting approximately 200 concurrent users. On the financial side, the estimated cost is just $0.002–$0.005 per query. This impressive efficiency was driven by the RAG architecture, which cut token consumption by 40–60% compared to making direct, context-less calls to a large LLM.
Final Takeaways
This partnership effort demonstrates how modern AI agent frameworks can bridge the gap between vast, complex knowledge repositories and everyday user needs.
First, RAG is a game-changer. For knowledge retrieval, it is not just an architectural pattern; it’s a direct driver of cost reduction and accuracy improvement.
Furthermore, leveraging a solid framework accelerates development. Using our SmythOS platform allowed us to focus on application logic and user experience rather than reinventing the core infrastructure for ingestion, retrieval, and scaling.
Finally, never underestimate the power of simple, robust logging. The act of logging queries to Google Sheets provided an invaluable audit trail. It allowed us to identify patterns (like users’ tendencies toward casual phrasing), debug edge cases, and create a data-driven feedback loop for continuous improvement.By transforming how information is accessed, this AI agent delivers clarity and accessibility to even the most complex subject matter, saving time and empowering users to find the answers they need, right when they need them.
Want to know more about how SmythOS can help your organization like we were able to with this partner? Reach out to our team for more information. Want to get involved with the SmythOS community? Check out our GitHub Repos and help build the future of Agentic AI.