It’s not the news many expected, but OpenAI just released two open-weight reasoning models: gpt-oss-120b and gpt-oss-20b. It’s not GPT-5, but it has certainly made a big splash.
Why?
These models are production-minded with 128k context models and agentic tools, and weights you can run or tune.
By making the models open, OpenAI provides the developer community with powerful tools that come with a long-awaited level of transparency. The models are compatible with OpenAI-compatible Responses API, and support features like full chain-of-thought (CoT) and structured outputs.
Now, let’s take a closer look at gpt-oss-120b and gpt-oss-20b.
What are the GPT OSS Models?
The GPT-OSS models are built on a Mixture-of-Experts (MoE) architecture. This approach has gained traction for a simple reason: its ability to create very large, yet computationally efficient, models.
The models come in two sizes: gpt-oss-120b, with 116.8 billion parameters, designed for large-scale infrastructure. And gpt-oss-20b, with 20.9 billion parameters, optimized for running on-device.
OpenAI noted that the 120b is near o4-mini on core reasoning, and 20b around o3-mini, with weights downloadable today.
One of the most practical aspects of their design is the use of MXFP4 quantization. This technique significantly reduces the model’s memory footprint without a substantial loss in performance.
The result? The massive gpt-oss-120b can run on a single 80GB GPU like an NVIDIA H100, while the gpt-oss-20b can operate on systems with as little as 16GB of memory. This is a game-changer for accessibility, putting powerful models within reach for more developers and researchers.
Furthermore, the models incorporate several modern architectural choices. They use Pre-LayerNorm (Pre-LN) for training stability, Gated SwiGLU activation functions for improved performance, and Grouped Query Attention (GQA) to speed up inference.
With a generous context length of 131,072 tokens, they are well-suited for tasks that require understanding long and complex inputs.
According to OpenAI, the models were trained on trillions of text tokens with a clear emphasis on STEM, coding, and general knowledge.
Unpacking the Benchmarks and Performance
OpenAI has tested the GPT-OSS models against a suite of well-regarded benchmarks, and the results paint a picture of highly capable, reasoning-focused tools.
The gpt-oss-120b model, in particular, shines in areas that demand deep reasoning. On the AIME benchmark for math problem-solving, it performs exceptionally well, a result OpenAI attributes to its effective use of long Chains of Thought (CoT).
In general knowledge and reasoning tasks like MMLU and GPQA, it proves to be a strong competitor, performing on par with OpenAI’s own gpt-4o-mini.
For developers, coding proficiency is paramount. Here, both models hold their own. They show strong results on the Codeforces and SWE-Bench benchmarks, again approaching the performance levels of gpt-4o-mini. Beyond code generation, the models demonstrate robust function-calling abilities, a critical feature for building agents and integrating with external tools. This was evident in their performance on the Tau-Bench Retail benchmark.
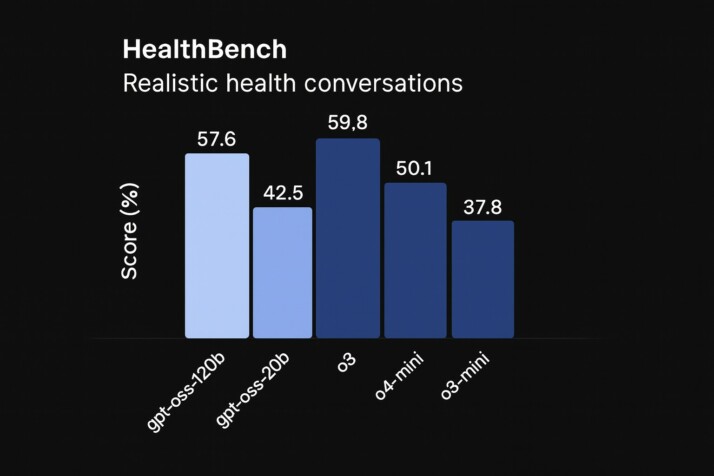
In addition, the gpt-oss-120b model shows competitive performance on HealthBench, a challenging medical question-answering benchmark, even outperforming some frontier models. The 120B beats o4-mini and o3-mini on HealthBench but trails o3. It also displays strong multilingual capabilities, with performance on the MMMLU benchmark that is nearly on par with gpt-4o-mini.
| Benchmark | gpt-oss-120b | gpt-oss-20b | ||||
|---|---|---|---|---|---|---|
| low | medium | high | low | medium | high | |
| Accuracy (%) | ||||||
| AIME 2024 (no tools) | 56.3 | 80.4 | 95.8 | 42.1 | 80.0 | 92.1 |
| AIME 2024 (with tools) | 75.4 | 87.9 | 96.6 | 61.2 | 86.0 | 96.0 |
| AIME 2025 (no tools) | 50.4 | 80.0 | 92.5 | 37.1 | 72.1 | 91.7 |
| AIME 2025 (with tools) | 72.9 | 91.6 | 97.9 | 57.5 | 90.4 | 98.7 |
| GPQA Diamond (no tools) | 67.1 | 73.1 | 80.1 | 56.8 | 66.0 | 71.5 |
| GPQA Diamond (with tools) | 68.1 | 73.5 | 80.9 | 58.0 | 67.1 | 74.2 |
| HLE (no tools) | 5.2 | 8.6 | 14.9 | 4.2 | 7.0 | 10.9 |
| HLE (with tools) | 9.1 | 11.3 | 19.0 | 6.3 | 8.8 | 17.3 |
| MMLU | 85.9 | 88.0 | 90.0 | 80.4 | 84.0 | 85.3 |
| SWE-Bench Verified | 47.9 | 52.6 | 62.4 | 37.4 | 53.2 | 60.7 |
| Tau-Bench Retail | 49.4 | 62.0 | 67.8 | 35.0 | 47.3 | 54.8 |
| Tau-Bench Airline | 42.6 | 48.6 | 49.2 | 32.0 | 42.6 | 38.0 |
| Aider Polyglot | 24.0 | 34.2 | 44.4 | 16.6 | 26.6 | 34.2 |
| MMMLU (Average) | 74.1 | 79.3 | 81.3 | 67.0 | 73.5 | 75.7 |
| Score (%) | ||||||
| HealthBench | 53.0 | 55.9 | 57.6 | 40.4 | 41.8 | 42.5 |
| HealthBench Hard | 22.8 | 26.9 | 30.0 | 9.0 | 12.9 | 10.8 |
| HealthBench Consensus | 90.6 | 90.8 | 89.9 | 84.9 | 83.0 | 82.6 |
| Elo | ||||||
| Codeforces (no tools) | 1595 | 2205 | 2463 | 1366 | 1998 | 2230 |
| Codeforces (with tools) | 1653 | 2365 | 2622 | 1251 | 2064 | 2516 |
Early feedback from the community seems to align with these findings, with testers showcasing the model’s ability to tackle complex logic puzzles and coding challenges.
While the gpt-oss-120b model is the clear performance leader, the gpt-oss-20b model offers a compelling balance of capability and efficiency. Hence, it’s a viable option for applications where resource constraints are a key consideration.
GPT-OSS-120B vs. GPT-OSS-20B
While both models share the same fundamental Mixture-of-Experts (MoE) architecture and a generous 128k context length, their primary differences lie in their scale and resource requirements.
The choice between them comes down to a classic trade-off: the enhanced performance of the larger model versus the efficiency and accessibility of the smaller one.
Gpt-oss-120b vs gpt-oss-20b
Both models use a Mixture-of-Experts transformer with 4 experts active per token and a native 128k context window.
The table below summarizes the core specs developers care about.
| Model | Layers | Total Params | Active Params Per Token | Total Experts | Active Experts Per Token | Context Length |
|---|---|---|---|---|---|---|
| gpt-oss-120b | 36 | 117B | 5.1B | 128 | 4 | 128k |
| gpt-oss-20b | 24 | 21B | 3.6B | 32 | 4 | 128k |
Rule of thumb: start on 20B for day-to-day workloads and escalate to 120B for the toughest reasoning steps or high-stakes answers.
A Developer’s Toolkit: Features and Capabilities
OpenAI equipped gpt-oss-120b and gpt-oss-20b with a toolkit that supports complex, multi-step workflows right out of the box. Here are some features that could come in handy:
Agentic Tool Use
At their core, these models are built to be agents. They come with built-in support for a Browse tool and a stateful Python notebook environment. This means the model can autonomously search for information or execute code to solve a problem. More importantly, developers can define and provide their arbitrary functions, allowing for seamless integration with any API or external data source.
Variable Effort Reasoning
One of the most intriguing features is the ability to configure the model’s “effort” level for reasoning. Developers can choose from three settings: low, medium, or high. This setting directly influences the length and complexity of the model’s internal Chain of Thought. A “low” setting will provide faster, more concise responses, suitable for simpler tasks. A “high” setting will prompt the model to generate a more detailed, step-by-step reasoning process, leading to better answers for complex problems at the cost of higher latency. This gives developers granular control over the trade-off between performance and cost.
Harmony Chat Format
To get the most out of these agentic features, OpenAI introduced the Harmony Chat Format. This is a custom, flexible chat structure that goes beyond the standard user/assistant turn-based conversation. It’s designed to handle complex interactions, allowing for the interleaving of tool calls, tool outputs, and the model’s internal monologue or Chain of Thought. Using this format is key to unlocking the full reasoning and tool-use potential of the models.
Structured Outputs
Finally, the models are capable of producing structured outputs, such as JSON. For anyone who has tried to reliably parse information from a large language model, the importance of this feature cannot be overstated. It simplifies the process of integrating the model’s output into other systems. This is essential for building predictable, production-ready applications.
Safety by Design
OpenAI has taken proactive steps to build safety into the models from the ground up. The pre-training data was filtered to remove harmful content, and the models were trained to adhere to OpenAI’s safety policies by default. This provides a baseline level of safety, but it’s not foolproof.
Open-Weight Risks and Adversarial Testing
The most significant risk with any powerful open-weight model is the potential for malicious actors to fine-tune it for harmful purposes. OpenAI doesn’t shy away from this. They conducted extensive adversarial testing, specifically looking at the risk of fine-tuning gpt-oss-120b for dangerous applications related to biological, chemical, and cybersecurity threats.
Their conclusion?
The model could be pushed to generate harmful content. But it did not reach “High capability” in these risk areas, even after being fine-tuned by experts trying to break it. This suggests that creating dangerous new threats with this model would still require significant, specialized human expertise. However, the risk is not zero. So, the collective responsibility of the community is to use these tools ethically.
Getting Your Hands on GPT-OSS
For developers eager to start building, the models are accessible. Both gpt-oss-120b and gpt-oss-20b are available now on the Hugging Face Hub, released under the permissive Apache 2.0 license. It’s highly recommended that you use the official open-source implementation provided by OpenAI. That way, you’ll get the best performance and unlock their full agentic capabilities.
This includes leveraging the Harmony Chat Format. It’s essential for the advanced tool-use and reasoning workflows the models were designed. As with any powerful tool, the invitation to build comes with a call for responsible innovation and adherence to the usage policies.
Conclusion
With a strong focus on reasoning, coding, and agentic workflows, gpt-oss-120b and gpt-oss-20b offer a robust foundation for the next wave of AI-powered applications. OpenAI is placing a new level of trust in the open-source ecosystem. This is an opportunity to collectively shape a future where powerful AI is developed and deployed responsibly. For developers, it’s a chance to get your hands dirty, to build, to test, and to contribute to that future. The next step is yours: wire them into your stack, measure, and keep what proves out.