
Kimi AI is a high-performance large language model developed by Moonshot AI, known for its massive context window. The latest version, Kimi K2, features significantly improved reasoning capabilities, specifically in coding and mathematics (GSM8K).
🔴 UPDATE (Jan 27, 2026): Kimi K2.5 is Now Live
Moonshot AI has officially introduced Kimi K2.5, their most powerful open-source model to date. Built on 15 trillion mixed visual and text tokens, K2.5 represents a transition from single-agent LLMs to a self-directed Agent Swarm paradigm. It can autonomously orchestrate up to 100 sub-agents to handle 1,500 parallel tool calls—delivering a 4.5x reduction in execution time.
Jump to Kimi K2.5 Technical Breakdown & Full Benchmarks.
Moonshot AI open‑sourced Kimi K2 on 11 July 2025. The goal is simple: hand off work that usually requires whole teams, such as debugging code, running data pipelines, and wiring up tools, to a single model built for action.
Kimi K2 ships in two checkpoints, namely Kimi‑K2‑Base and Kimi‑K2‑Instruct. Let’s take a look at what this AI model has to offer.
What is Kimi AI?
Kimi AI is a high-capacity artificial intelligence ecosystem developed by Moonshot AI. While initially famous for its massive context windows (up to 10 million tokens), the brand has evolved into a leading developer of multimodal reasoning models. The current lineup includes the original Kimi (long-context reading), Kimi K2 (agentic reasoning), and Kimi K2.5 (visual intelligence and agent swarms).
What Is the KIMI K2 Open-Source Model? Inside the Stack
Moonshot promises “advanced agentic intelligence” with the Kimi‑K2‑Base for custom fine‑tuning and Kimi‑K2‑Instruct for immediate production use. However, both variants share identical internals.
K2 is a Mixture‑of‑Experts transformer model with 1 trillion total parameters, but a router lights up only 32 billion on any token.
Basically, the network spans 61 transformer layers with 384 experts sitting behind them. The router picks eight experts per token, so each forward pass feels more like a slim‑line 30‑odd‑b model in latency and cost.
The model keeps 64 attention heads, switches on a SwiGLU activation, and speaks a 160 k‑token vocabulary. Thanks to Multi‑head Latent Attention (MLA), the context window stretches to 128 k tokens. This means the model reads an entire codebase or multi‑document brief in one go.
Training at this scale stayed stable because Moonshot swapped the usual AdamW for its Muon optimizer. Now paired with a MuonClip tweak that clips runaway attention logits and flattens loss spikes. What does this mean? Well, no training crashes even at trillion‑parameter breadth.
Taken together, these design choices give K2 a head start while keeping inference costs in line with those of mid-sized dense models. That efficiency is what unlocks its “agentic” edge: coding, tool use, and long‑horizon reasoning. All without locking you into a black‑box vendor!
How Does It Differ from Other Open Source Models?
So what’s new here, and how does it compare to other heavyweight models on the market? Here’s the rundown of exactly what Kimi K2 offers, and why it matters.
Is Kimi K2 Open Source? License and Access
Unlike proprietary models such as Claude or GPT-4, Kimi K2 arrives fully open under a permissive MIT-style license.
In other words, you can inspect every parameter and fine-tune it for your specific use cases. Or better still, host the model yourself. Moonshot also ensured compatibility by offering an OpenAI- and Anthropic-compatible API.
Kimi K2 provides genuine transparency and complete ownership of your AI pipeline.
Mixture-of-Experts Architecture
As we said earlier, Kimi K2 incorporates a “Mixture-of-Experts” (MoE) approach with 1 trillion parameters. However, only 32 billion parameters activate per token, managed efficiently by an internal routing mechanism.
This means you gain the knowledge and reasoning abilities of a trillion-parameter model while incurring only a fraction of the typical computational cost. It’s roughly equivalent to running a much smaller, dense model.
This design differs from traditional “dense” models like GPT-4 and Claude. Moonshot is offering large-model capabilities without an equally large infrastructure burden.
MuonClip Optimizer
Training AI at the trillion-parameter scale is fragile. Instabilities like exploding attention logits can crash training or corrupt model quality halfway through.
To address this, Moonshot introduced MuonClip, an optimizer that builds on their earlier work with Muon. Its core innovation is a technique called qk-clip, which rescales the query and key weight matrices after each optimizer step.
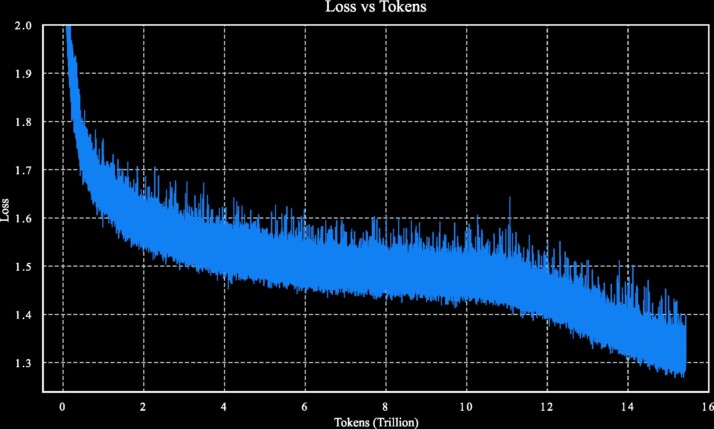
This keeps the attention logits from spiraling out of control during training. A common failure mode in large, sparse models. That way, the Kimi K2 was trained on 15.5 trillion tokens without a single training spike. Undoubtedly, this is a technical win at scale.
128,000-Token Context
One of the most limiting factors in traditional AI models is context length. Kimi K2 addresses this with Multi-head Latent Attention (MLA), supporting up to 128,000 tokens in a single prompt.
That’s enough to feed an entire codebase, a legal case file, or multiple research papers without breaking things into chunks.
This removes workarounds, reduces complexity, and makes large-scale reasoning much easier to deploy for developers and teams building real tools.
Deployment-Ready From Day One
Moonshot offers Kimi K2 in block‑FP8 format, optimized for inference and compatible with vLLM, SGLang, KTransformers, and TensorRT‑LLM. They don’t mandate specific hardware. However, the model’s architecture favors multi‑GPU server setups, typically using NVIDIA H100 or H200, for smooth, high‑throughput deployment.
Single‑GPU use is possible but demanding, given the model’s trillion‑parameter MoE design. Still, expert routing and quantization keep Kimi K2 far more efficient than dense models of similar scale. The focus here is practical. Kimi K2 is meant to run in the real world.
Kimi K2 Performance: Benchmarks and GSM8K Scores
The Kimi K2 Instruct model scores a record-breaking 94.4% on the GSM8K (Grade School Math 8K) benchmark. This performance places Moonshot AI’s Kimi K2 ahead of both GPT-4.1 (91.8%) and Claude Opus 4 (93.5%) in mathematical reasoning and logic.
KIMI K2 Instruct vs Others
| Category | Benchmark (metric) | Kimi K2 Instruct | Claude Opus 4 | GPT‑4.1 |
|---|---|---|---|---|
| Coding | SWE‑Bench Verified · single‑attempt Pass @ 1 | 65.8 % | 72.5 % | 54.6 % |
| LiveCodeBench v6 · Pass @ 1 | 53.7 % | 47.4 % | 44.7 % | |
| MultiPL‑E · Pass @ 1 | 85.7 % | 89.6 % | 86.7 % | |
| Tool use | Tau2 (retail) · Avg @ 4 | 70.6 % | 81.8 % | 74.8 % |
| AceBench · Accuracy | 76.5 % | 75.6 % | 80.1 % | |
| Math & STEM | GSM8k · EM (8‑shot) | 94.4 % | 93.5 % | 91.8 % |
| MATH‑500 · Accuracy | 97.4 % | 94.4 % | 92.4 % | |
| ZebraLogic · Accuracy | 89.0 % | 59.3 % | 58.5 % | |
| GPQA‑Diamond · Avg @ 8 | 75.1 % | 74.9 % | 66.3 % | |
| General knowledge | MMLU · Exact‑Match | 89.5 % | 92.9 % | 90.4 % |
Let’s give the Base checkpoint its spotlight. For reference, here’s how the raw, unfine‑tuned K2‑Base stacks up against the strongest open checkpoints before any instruction‑tuning
Kimi K2 Base vs. Flagship Closed Models
| Benchmark (metric) | Kimi K2 Base | DeepSeek‑V3 Base | Qwen 2.5‑72B | Llama‑4 Maverick |
|---|---|---|---|---|
| MMLU · EM (5‑shot) | 87.8 % | 87.1 % | 86.1 % | 84.9 % |
| MMLU‑Pro · EM (5‑shot) | 69.2 % | 60.6 % | 62.8 % | 63.5 % |
| MATH · EM (4‑shot) | 70.2 % | 60.1 % | 61.0 % | 63.0 % |
| GSM8k · EM (8‑shot) | 92.1 % | 91.7 % | 90.4 % | 86.3 % |
| LiveCodeBench v6 · Pass @ 1 | 26.3 % | 22.9 % | 21.1 % | 25.1 % |
| EvalPlus · Pass @ 1 | 80.3 % | 65.6 % | 66.0 % | 65.5 % |
| TriviaQA · EM (5‑shot) | 85.1 % | 84.1 % | 76.0 % | 79.3 % |
Kimi K2.5: Visual Agentic Intelligence and Swarms
The leap from K2 to K2.5 focuses on multimodal pre-training and parallel execution. Kimi K2.5 is designed to function as a self-directed orchestrator for complex developer tasks.
- Native Multimodality: K2.5 reasons across mixed visual and text tokens, enabling autonomous visual debugging. It can visually inspect front-end interfaces it builds and iterate on the code in real-time.
- Agent Swarm Paradigm: Unlike single-agent models, K2.5 creates a swarm of up to 100 sub-agents. Using Parallel-Agent Reinforcement Learning (PARL), it decomposes tasks into sub-tasks, reducing latency significantly.
- Kimi Code Integration: K2.5 is optimized for the terminal and IDEs (VSCode, Cursor), supporting vision-to-code generation and massive codebase reasoning via its 2M+ context window.
Kimi K2.5 Official Benchmarks (Jan 2026)
In agentic reasoning benchmarks like HLE-Full (Humanity’s Last Exam), Kimi K2.5 has officially surpassed proprietary leaders like GPT-5.2 and Claude 4.5 Opus.
| Benchmark | Kimi K2.5 (Thinking) | GPT-5.2 (xhigh) | Claude 4.5 Opus (Extend Thinking) | Gemini 3 Pro (High Thinking Level) | DeepSeek V3.2 (Thinking) | Qwen3-VL-235B-A22B (Thinking) |
|---|---|---|---|---|---|---|
| Reasoning & Knowledge | ||||||
| HLE-Full | 30.1 | 34.5 | 30.8 | 37.5 | 25.1* | — |
| HLE-Full w/ tools | 50.2 | 45.5 | 43.2 | 45.8 | 40.8* | — |
| AIME 2025 | 96.1 | 100.0 | 92.8 | 95.0 | 93.1 | — |
| HMMT 2025 (Feb) | 95.4 | 99.4 | 92.9* | 97.3* | 92.5 | — |
| IMO-AnswerBench | 81.8 | 86.3 | 78.5* | 83.1* | 78.3 | — |
| GPQA-Diamond | 87.6 | 92.4 | 87.0 | 91.9 | 82.4 | — |
| MMLU-Pro | 87.1 | 86.7* | 89.3* | 90.1 | 85.0 | — |
| Image & Video | ||||||
| MMMU-Pro | 78.5 | 79.5 | 74.0 | 81.0 | — | 69.3 |
| CharXiv (RQ) | 77.5 | 82.1 | 67.2* | 81.4 | — | 66.1 |
| MathVision | 84.2 | 83.0 | 77.1* | 86.1 | — | 74.6 |
| MathVista (mini) | 90.1 | 82.8* | 80.2* | 89.8* | — | 85.8 |
| ZeroBench | 9.0 | 9.0* | 3.0* | 8.0* | — | 4.0* |
| ZeroBench w/ tools | 11.0 | 7.0* | 9.0* | 12.0* | — | 3.0* |
| OCRBench | 92.3 | 80.7* | 86.5* | 90.3* | — | 87.5 |
| OmniDocBench 1.5 | 88.8 | 85.7 | 87.7* | 88.5 | — | 82.0* |
| InfoVQA (test) | 92.6 | 84.0* | 76.9* | 57.2* | — | 89.5 |
| SimpleVQA | 71.2 | 55.8* | 69.7* | 69.7* | — | 56.8* |
| WorldVQA | 46.3 | 28.0 | 36.8 | 47.4 | — | 23.5 |
| VideoMMMU | 86.6 | 85.9 | 84.4* | 87.6 | — | 80.0 |
| MMVU | 80.4 | 80.8* | 77.3 | 77.5 | — | 71.1 |
| MotionBench | 70.4 | 64.8 | 60.3 | 70.3 | — | — |
| VideoMME | 87.4 | 86.0 | — | 88.4* | — | 79.0 |
| LongVideoBench | 79.8 | 76.5 | 67.2 | 77.7* | — | 65.6* |
| LVBench | 75.9 | — | — | 73.5* | — | 63.6 |
| Coding | ||||||
| SWE-Bench Verified | 76.8 | 80.0 | 80.9 | 76.2 | 73.1 | — |
| SWE-Bench Pro | 50.7 | 55.6 | 55.4* | — | — | — |
| SWE-Bench Multilingual | 73.0 | 72.0 | 77.5 | 65.0 | 70.2 | — |
| Terminal-Bench 2.0 | 50.8 | 54.0 | 59.3 | 54.2 | 46.4 | — |
| PaperBench | 63.5 | 63.7* | 72.9* | — | 47.1 | — |
| CyberGym | 41.3 | — | 50.6 | 39.9* | 17.3* | — |
| SciCode | 48.7 | 52.1 | 49.5 | 56.1 | 38.9 | — |
| OJBench (cpp) | 57.4 | — | 54.6* | 68.5* | 54.7* | — |
| LiveCodeBench (v6) | 85.0 | — | 82.2* | 87.4* | 83.3 | — |
| Long Context | ||||||
| Longbench v2 | 61.0 | 54.5* | 64.4* | 68.2* | 59.8* | — |
| AA-LCR | 70.0 | 72.3* | 71.3* | 65.3* | 64.3* | — |
| Agentic Search | ||||||
| BrowseComp | 60.6 | — | 37.0 | 37.8 | 51.4 | — |
| BrowseComp (w/ctx mgm) | 74.9 | 65.8 | 57.8 | 59.2 | 67.6 | — |
| BrowseComp (Agent Swarm) | 78.4 | — | — | — | — | — |
| WideSearch (item-f1) | 72.7 | — | 76.2* | 57.0 | 32.5* | — |
| WideSearch (item-f1) (Agent Swarm) | 79.0 | — | — | — | — | — |
| DeepSearchQA | 77.1 | 71.3* | 76.1* | 63.2* | 60.9* | — |
| FinSearchCompT2&T3 | 67.8 | — | 66.2* | 49.9 | 59.1* | — |
| Seal-0 | 57.4 | 45.0 | 47.7* | 45.5* | 49.5* | — |
| Computer Use | ||||||
| OSWorld-Verified | 63.3 | 8.6* | 66.3 | 20.7* | — | 38.1 |
| WebArena | 58.9 | — | 63.4* | — | — | 26.4* |
- Benchmarks without publicly available scores were re-evaluated under the same conditions used for Kimi K2.5 and are marked with an asterisk (*).
- GPT-5.2 xhigh could not be evaluated on all benchmarks due to service stability issues. Benchmarks that were not tested are marked as “—”.
Known Limitations and Trade-offs
Moonshot explicitly notes a few known limitations in the current Kimi K2 model:
Excessive Token Generation
For challenging reasoning tasks or situations where tool definitions are unclear, Kimi K2 sometimes generates too many tokens. This can lead to responses being truncated or tool calls being incomplete.
Performance Decline With Tool Use
In certain scenarios, enabling tool integration negatively affects the model’s overall performance, causing it to underperform compared to tool-free contexts.
Reduced Effectiveness of One-shot Prompting
When tasked with building complete software projects, Kimi K2 shows decreased performance if given instructions in a single prompt (one-shot prompting). Rather than through a structured, step-by-step agentic workflow.
Hallucination & Stubborn Replying
Users on r/LocalLLaMA report Kimi K2 “frequently made things up… insisted it was correct” even when it wasn’t, refusing to reconsider until challenged. That suggests the model can cling to incorrect assumptions rather than self-correct reflexively.
Slow Token Generation
In production environments (e.g., Cursor + Fireworks), users observed that K2’s token generation was significantly slower than competitors.
One user claimed that requests like “creating two readme.md files” could take 15–17 minutes or even fail outright. This highlights a gap between theoretical throughput and real-world speed.
Note that Moonshot openly acknowledges some of these limitations and states they’re actively working to resolve these issues in upcoming releases. Moonshot would also love feedback to keep rolling in as they continue refining the model.
Bottom line
Kimi K2 swaps the comfort of a paid API for total control, stronger coding chops, and a genuine tool‑use brain. If you have the appetite for ownership, it’s ready to work hard for you.
With the K2.5 update, Kimi AI has moved from a “long-context curiosity” to a production-grade Agentic Swarm powerhouse. For developers on SmythOS, the ability to deploy K2.5’s self-directed sub-agents means shifting from building sequential pipelines to managing high-speed, parallelized autonomous teams.
Kimi AI is a large language model ecosystem by Moonshot AI, specifically optimized for long-context processing (up to 10 million tokens) and agentic reasoning.
Kimi K2 is released under a permissive MIT-style license, making it an “open-weights” model that developers can customize and host locally.
The Kimi K2 Instruct model scores 94.4% on the GSM8K mathematical reasoning benchmark, making it one of the most capable models for technical and logic-based tasks.
Moonshot AI released Kimi K2.5 on January 27, 2026. It is a native multimodal model trained on 15 trillion tokens, featuring significant upgrades in visual reasoning and coding.
It is a self-directed parallel execution framework where Kimi K2.5 acts as an orchestrator, dynamically creating up to 100 specialized sub-agents to solve complex tasks. This reduces wall-clock execution time by up to 4.5x compared to single-agent systems.